Ole Begemann
Roy fielding’s rest dissertation.
I recently read Roy Fielding’s 2000 PhD thesis, Architectural Styles and the Design of Network-based Software Architectures , in which he introduced and described REST . Here’s what I learned.
REST is almost as old as the web. I first heard of REST around 2005 while working with Rails . As mentioned, Fielding’s dissertation is from 2000, but he began developing the ideas that later became REST as early as 1994.
REST didn’t come out of nowhere. Roy Fielding wasn’t some random PhD student who sat in his ivory tower and came up with a bright idea. He was deeply involved in the web’s early development and standardization. Starting in 1994, Fielding began working at and for the World Wide Web Consortium and co-authored the HTTP 1.0 specification. In the second half of the 1990s, Fielding was the main author behind the HTTP 1.1 and URI specs. He also co-founded the Apache web server project.
REST is the web’s architecture. REST isn’t specifically about web services (i.e. machine-readable APIs that return JSON or XML). In fact, Fielding doesn’t really mention web APIs in his dissertation.
Rather, REST is first and foremost a description of the web’s architecture. The entire web is supposed to be RESTful. Specifying the web (as defined in the HTTP 1.1 spec ) is the original purpose for which REST was developed.
Since 1994, the REST architectural style has been used to guide the design and development of the architecture for the modern Web. This work was done in conjunction with my authoring of the Internet standards for the Hypertext Transfer Protocol (HTTP) and Uniform Resource Identifiers (URI), the two specifications that define the generic interface used by all component interactions on the Web. — Roy Fielding, Architectural Styles and the Design of Network-based Software Architectures, p. 107.
The original name for REST was the “HTTP object model”:
REST was originally referred to as the “HTTP object model,” but that name would often lead to misinterpretation of it as the implementation model of an HTTP server. The name “Representational State Transfer” is intended to evoke an image of how a well-designed Web application behaves: a network of web pages (a virtual state-machine), where the user progresses through the application by selecting links (state transitions), resulting in the next page (representing the next state of the application) being transferred to the user and rendered for their use. — ibid., p. 109.

Architectural constraints
REST is defined through constraints. Any communication architecture that wants to call itself RESTful must abide by these constraints. You can read the full list on the Wikipedia page . Here, I’ll just list the ones I find most important.
Statelessness
Each request must contain all of the information necessary for the server to understand the request, and cannot take advantage of any stored context on the server. Session state is kept entirely on the client. Statelessness makes a service more reliable and easier to scale.
Fielding notes that cookies violate REST. To him, the presence of cookies is an unfortunate mismatch between the ideals of REST and the reality of HTTP:
An example of where an inappropriate extension has been made to the protocol [HTTP] to support features that contradict the desired properties of the generic interface is the introduction of site-wide state information in the form of HTTP cookies. Cookie interaction fails to match REST’s model of application state, often resulting in confusion for the typical browser application. — ibid., p. 130.
Cacheability
Requests and responses must include information about their cacheability. If a response is marked as cacheable, the client (or any node sitting between server and client) is allowed to reuse the data for later requests.
Fielding’s focus in the dissertation is markedly different from how developers discuss REST today. He spends a lot of time discussing web characteristics like cacheability, scalability, and the transparency of messages to intermediaries (proxies), whereas the finer points of POST vs. PUT vs. PATCH play no role in the thesis. In fact, he doesn’t mention the different HTTP methods at all.
Resources and representations
Identification of resources. Resources are the key abstraction of REST. This is in constrast to earlier specifications of the web, which used the term document for an individual “unit of content”. Resources are a more generic concept than documents. For example, having the URI to a document implies that the document exists, while a resource identifier can be valid before the resource exists (e.g. a client could pass a URI of a non-existent resource to create it).
A resource is a conceptual mapping to a set of concrete entities. For example, “today’s weather” is a valid resource, even though the concrete piece of information it maps to changes every day. Each resource has a unique identifier (usually a URI ).
Manipulation of resources through representations. Since resources can be abstract concepts, a resource itself is never directly manipulated or sent over the network. Instead, server and client exchange representations of resources. The server can (and should) offer multiple representations (e.g. JSON and XML) of the same resource. Clients tell the server which representation formats they understand.
REST components communicate by transferring a representation of a resource in a format matching one of an evolving set of standard data types , selected dynamically based on the capabilities or desires of the recipient and the nature of the resource. Whether the representation is in the same format as the raw source, or is derived from the source, remains hidden behind the interface. — ibid., p. 87.
Self-descriptive messages
Messages include enough information to describe how their payload is to be processed (e.g. media type information must be part of each message). Also, each message completely identifies the resource it concerns (this wasn’t the case in the early days of HTTP when the HTTP header didn’t contain the hostname because it was assumed that there was a 1:1 mapping between IP addresses and hostnames).
Hypermedia as the engine of application state
The central idea behind HATEOAS is that RESTful servers and clients shouldn’t rely on a hardcoded interface (that they agreed upon through a separate channel). Instead, the server is supposed to send the set of URIs representing possible state transitions with each response, from which the client can select the one it wants to transition to. This is exactly how web browsers work:
The model application is therefore an engine that moves from one state to the next by examining and choosing from among the alternative state transitions in the current set of representations. Not surprisingly, this exactly matches the user interface of a hypermedia browser. — ibid. , p. 103.
For web services where two machines talk to each other without a human controlling the interaction, I have a harder time imagining how this is supposed to work. How can you develop a client for a specific API without hardcoding some knowledge about the expected resource types? Fielding doesn’t elaborate on this in his thesis.
However, he later clarified in a 2008 blog post that APIs must be hypertext-driven to legitimately call themselves RESTful:
A REST API should be entered with no prior knowledge beyond the initial URI and set of standardized media types. From that point on, all application state transitions must be driven by client selection of server-provided choices that are present in the received representations or implied by the user’s manipulation of those representations. The transitions may be determined (or limited by) the client’s knowledge of media types and resource communication mechanisms, both of which may be improved on-the-fly (e.g., code-on-demand).
I’m still not sure how anybody can develop e.g. a great mobile app under these constraints that provides a specialized user interface for one particular service. If you don’t have any out-of-band knowledge about the service you’re interacting with, you’re basically reimplementing a web browser.
PhotoKit’s data model
September 28, 2018
Splitting a Swift Sequence into head and tail
November 29, 2018
Two-Bit History
Computing through the ages

Roy Fielding's Misappropriated REST Dissertation
28 Jun 2020
RESTful APIs are everywhere. This is funny, because how many people really know what “RESTful” is supposed to mean?
I think most of us can empathize with this Hacker News poster :
I’ve read several articles about REST, even a bit of the original paper. But I still have quite a vague idea about what it is. I’m beginning to think that nobody knows, that it’s simply a very poorly defined concept.
I had planned to write a blog post exploring how REST came to be such a dominant paradigm for communication across the internet. I started my research by reading Roy Fielding’s 2000 dissertation , which introduced REST to the world. After reading Fielding’s dissertation, I realized that the much more interesting story here is how Fielding’s ideas came to be so widely misunderstood.
Many more people know that Fielding’s dissertation is where REST came from than have read the dissertation (fair enough), so misconceptions about what the dissertation actually contains are pervasive.
The biggest of these misconceptions is that the dissertation directly addresses the problem of building APIs. I had always assumed, as I imagine many people do, that REST was intended from the get-go as an architectural model for web APIs built on top of HTTP. I thought perhaps that there had been some chaotic experimental period where people were building APIs on top of HTTP all wrong, and then Fielding came along and presented REST as the sane way to do things. But the timeline doesn’t make sense here: APIs for web services, in the sense that we know them today, weren’t a thing until a few years after Fielding published his dissertation.
Fielding’s dissertation (titled “Architectural Styles and the Design of Network-based Software Architectures”) is not about how to build APIs on top of HTTP but rather about HTTP itself. Fielding contributed to the HTTP/1.0 specification and co-authored the HTTP/1.1 specification, which was published in 1999. He was interested in the architectural lessons that could be drawn from the design of the HTTP protocol; his dissertation presents REST as a distillation of the architectural principles that guided the standardization process for HTTP/1.1. Fielding used these principles to make decisions about which proposals to incorporate into HTTP/1.1. For example, he rejected a proposal to batch requests using new MGET and MHEAD methods because he felt the proposal violated the constraints prescribed by REST, especially the constraint that messages in a REST system should be easy to proxy and cache. 1 So HTTP/1.1 was instead designed around persistent connections over which multiple HTTP requests can be sent. (Fielding also felt that cookies are not RESTful because they add state to what should be a stateless system, but their usage was already entrenched. 2 ) REST, for Fielding, was not a guide to building HTTP-based systems but a guide to extending HTTP.
This isn’t to say that Fielding doesn’t think REST could be used to build other systems. It’s just that he assumes these other systems will also be “distributed hypermedia systems.” This is another misconception people have about REST: that it is a general architecture you can use for any kind of networked application. But you could sum up the part of the dissertation where Fielding introduces REST as, essentially, “Listen, we just designed HTTP, so if you also find yourself designing a distributed hypermedia system you should use this cool architecture we worked out called REST to make things easier.” It’s not obvious why Fielding thinks anyone would ever attempt to build such a thing given that the web already exists; perhaps in 2000 it seemed like there was room for more than one distributed hypermedia system in the world. Anyway, Fielding makes clear that REST is intended as a solution for the scalability and consistency problems that arise when trying to connect hypermedia across the internet, not as an architectural model for distributed applications in general.
We remember Fielding’s dissertation now as the dissertation that introduced REST, but really the dissertation is about how much one-size-fits-all software architectures suck, and how you can better pick a software architecture appropriate for your needs. Only a single chapter of the dissertation is devoted to REST itself; much of the word count is spent on a taxonomy of alternative architectural styles 3 that one could use for networked applications. Among these is the Pipe-and-Filter (PF) style, inspired by Unix pipes, along with various refinements of the Client-Server style (CS), such as Layered-Client-Server (LCS), Client-Cache-Stateless-Server (C$SS), and Layered-Client-Cache-Stateless-Server (LC$SS). The acronyms get unwieldy but Fielding’s point is that you can mix and match constraints imposed by existing styles to derive new styles. REST gets derived this way and could instead have been called—but for obvious reasons was not—Uniform-Layered-Code-on-Demand-Client-Cache-Stateless-Server (ULCODC$SS). Fielding establishes this taxonomy to emphasize that different constraints are appropriate for different applications and that this last group of constraints were the ones he felt worked best for HTTP.
This is the deep, deep irony of REST’s ubiquity today. REST gets blindly used for all sorts of networked applications now, but Fielding originally offered REST as an illustration of how to derive a software architecture tailored to an individual application’s particular needs.
I struggle to understand how this happened, because Fielding is so explicit about the pitfalls of not letting form follow function. He warns, almost at the very beginning of the dissertation, that “design-by-buzzword is a common occurrence” brought on by a failure to properly appreciate software architecture. 4 He picks up this theme again several pages later:
Some architectural styles are often portrayed as “silver bullet” solutions for all forms of software. However, a good designer should select a style that matches the needs of a particular problem being solved. 5
REST itself is an especially poor “silver bullet” solution, because, as Fielding later points out, it incorporates trade-offs that may not be appropriate unless you are building a distributed hypermedia application:
REST is designed to be efficient for large-grain hypermedia data transfer, optimizing for the common case of the Web, but resulting in an interface that is not optimal for other forms of architectural interaction. 6
Fielding came up with REST because the web posed a thorny problem of “anarchic scalability,” by which Fielding means the need to connect documents in a performant way across organizational and national boundaries. The constraints that REST imposes were carefully chosen to solve this anarchic scalability problem. Web service APIs that are public-facing have to deal with a similar problem, so one can see why REST is relevant there. Yet today it would not be at all surprising to find that an engineering team has built a backend using REST even though the backend only talks to clients that the engineering team has full control over. We have all become the architect in this Monty Python sketch , who designs an apartment building in the style of a slaughterhouse because slaughterhouses are the only thing he has experience building. (Fielding uses a line from this sketch as an epigraph for his dissertation: “Excuse me… did you say ‘knives’?”)
So, given that Fielding’s dissertation was all about avoiding silver bullet software architectures, how did REST become a de facto standard for web services of every kind?
My theory is that, in the mid-2000s, the people who were sick of SOAP and wanted to do something else needed their own four-letter acronym.
I’m only half-joking here. SOAP, or the Simple Object Access Protocol, is a verbose and complicated protocol that you cannot use without first understanding a bunch of interrelated XML specifications. Early web services offered APIs based on SOAP, but, as more and more APIs started being offered in the mid-2000s, software developers burned by SOAP’s complexity migrated away en masse.
Among this crowd, SOAP inspired contempt. Ruby-on-Rails dropped SOAP support in 2007, leading to this emblematic comment from Rails creator David Heinemeier Hansson: “We feel that SOAP is overly complicated. It’s been taken over by the enterprise people, and when that happens, usually nothing good comes of it.” 7 The “enterprise people” wanted everything to be formally specified, but the get-shit-done crowd saw that as a waste of time.
If the get-shit-done crowd wasn’t going to use SOAP, they still needed some standard way of doing things. Since everyone was using HTTP, and since everyone would keep using HTTP at least as a transport layer because of all the proxying and caching support, the simplest possible thing to do was just rely on HTTP’s existing semantics. So that’s what they did. They could have called their approach Fuck It, Overload HTTP (FIOH), and that would have been an accurate name, as anyone who has ever tried to decide what HTTP status code to return for a business logic error can attest. But that would have seemed recklessly blasé next to all the formal specification work that went into SOAP.
Luckily, there was this dissertation out there, written by a co-author of the HTTP/1.1 specification, that had something vaguely to do with extending HTTP and could offer FIOH a veneer of academic respectability. So REST was appropriated to give cover for what was really just FIOH.
I’m not saying that this is exactly how things happened, or that there was an actual conspiracy among irreverent startup types to misappropriate REST, but this story helps me understand how REST became a model for web service APIs when Fielding’s dissertation isn’t about web service APIs at all. Adopting REST’s constraints makes some sense, especially for public-facing APIs that do cross organizational boundaries and thus benefit from REST’s “uniform interface.” That link must have been the kernel of why REST first got mentioned in connection with building APIs on the web. But imagining a separate approach called “FIOH,” that borrowed the “REST” name partly just for marketing reasons, helps me account for the many disparities between what today we know as RESTful APIs and the REST architectural style that Fielding originally described.
REST purists often complain, for example, that so-called REST APIs aren’t actually REST APIs because they do not use Hypermedia as The Engine of Application State (HATEOAS). Fielding himself has made this criticism . According to him, a real REST API is supposed to allow you to navigate all its endpoints from a base endpoint by following links. If you think that people are actually out there trying to build REST APIs, then this is a glaring omission—HATEOAS really is fundamental to Fielding’s original conception of REST, especially considering that the “state transfer” in “Representational State Transfer” refers to navigating a state machine using hyperlinks between resources (and not, as many people seem to believe, to transferring resource state over the wire). 8 But if you imagine that everyone is just building FIOH APIs and advertising them, with a nudge and a wink, as REST APIs, or slightly more honestly as “RESTful” APIs, then of course HATEOAS is unimportant.
Similarly, you might be surprised to know that there is nothing in Fielding’s dissertation about which HTTP verb should map to which CRUD action, even though software developers like to argue endlessly about whether using PUT or PATCH to update a resource is more RESTful. Having a standard mapping of HTTP verbs to CRUD actions is a useful thing, but this standard mapping is part of FIOH and not part of REST.
This is why, rather than saying that nobody understands REST, we should just think of the term “REST” as having been misappropriated. The modern notion of a REST API has historical links to Fielding’s REST architecture, but really the two things are separate. The historical link is good to keep in mind as a guide for when to build a RESTful API. Does your API cross organizational and national boundaries the same way that HTTP needs to? Then building a RESTful API with a predictable, uniform interface might be the right approach. If not, it’s good to remember that Fielding favored having form follow function. Maybe something like GraphQL or even just JSON-RPC would be a better fit for what you are trying to accomplish.
If you enjoyed this post, more like it come out every four weeks! Follow @TwoBitHistory on Twitter or subscribe to the RSS feed to make sure you know when a new post is out.
Previously on TwoBitHistory…
New post is up! I wrote about how to solve differential equations using an analog computer from the '30s mostly made out of gears. As a bonus there's even some stuff in here about how to aim very large artillery pieces. https://t.co/fwswXymgZa — TwoBitHistory (@TwoBitHistory) April 6, 2020
Roy Fielding. “Architectural Styles and the Design of Network-based Software Architectures,” 128. 2000. University of California, Irvine, PhD Dissertation, accessed June 28, 2020, https://www.ics.uci.edu/~fielding/pubs/dissertation/fielding_dissertation_2up.pdf . ↩
Fielding, 130. ↩
Fielding distinguishes between software architectures and software architecture “styles.” REST is an architectural style that has an instantiation in the architecture of HTTP. ↩
Fielding, 2. ↩
Fielding, 15. ↩
Fielding, 82. ↩
Paul Krill. “Ruby on Rails 2.0 released for Web Apps,” InfoWorld. Dec 7, 2007, accessed June 28, 2020, https://www.infoworld.com/article/2648925/ruby-on-rails-2-0-released-for-web-apps.html ↩
Fielding, 109. ↩
Roy T. Fielding: Understanding the REST Style
Ieee account.
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
The History of REST APIs
In 1999, the API environment was a free-for-all.
At that point, most developers had to deal with SOAP (Simple Object Access Protocol) to integrate APIs. And the “simple” part of that acronym is not to be taken literally. To make a call, they had to hand-write an XML document with an RPC call in the body. From there, they had to specify the endpoint and POST their SOAP envelope to that specified endpoint.
A super simple SOAP API request looks something like this:
POST http://soapl.develop.com/cgi-bin/ServerDemo.pl?class=Geometry HTTP/1.0 SOAPMethodName: http://soapl.develop.com/cgi-bin/ServerDemo.pl?class=Geometry#calculateArea Host: soapl.develop.com ( http://soapl.develop.com/ ) Content-Type: text/xml Content-Length: 494

If it looks nonsensical to you, it should. All of this is put together in accordance with an arbitrary set of guidelines specified in the documentation, which explains the transport bindings, types of data that can be accessed, parameter lists, operation names, and the endpoint URI. And if the call doesn't work, there aren't any HTTP respond codes to nudge you in the right direction.
SOAP was notorious for being complex to build, complex to use, and near-impossible to debug. And the alternative, CORBA, was even worse. The problem was that there was no standard for how APIs should be designed and used. Back then, APIs were not designed to be accessible, they were only designed to be flexible.
But a small group of expert developers recognized the true potential of web APIs. Thanks to this small group, led by Roy Fielding, REST was coined and the API landscape changed forever.
Here's how it all went down:
The Birth of REST: Roy Fielding's Dissertation
In 2000, Roy Fielding and his colleagues had one objective: Create a standard, so any server could talk to any other server in the world. Here's what he came up with in his doctoral dissertation :
I had comments from well over 500 developers, many of whom were distinguished engineers with decades of experience, and I had to explain everything from the most abstract notions of Web interaction to the finest details of HTTP syntax. That process honed my model down to a core set of principles, properties, and constraints that are now called REST.
- Uniform interface. This means we always use HTTP verbs (GET, PUT, POST, DELETE). We always use URIs as our resources. And we always get an HTTP response with a status and a body.
- Stateless. This means each request is self-descriptive, and has enough context for the server to process that message.
- Client-server. There has to be clear boundaries between roles of the two two systems. One server, operationally, has to function as the server that is being called, and the other has to function as the one making the requests.
- Cacheable. Unless denoted, a client can cache any representation. This is possible thanks to the statelessness—every representation is self-descriptive.
Another important difference between REST and SOAP is that it's resource-based, so the API accesses nouns (aka URIs), instead of verbs. Then, HTTP verbs are used to access those resources.
It seems like there are a lot of rules, but those rules are universal. It forces the API to be simpler, and makes the learning curve for developers trying to integrate software significantly less steep. Roy Fielding gave the disorganized internet world the gift of a common language through which their software could communicate.
Learning to Make Money from an API
Salesforce was technically the first company to sell an API as part of their “internet as a service” package in 2000, but few developer teams were able to take advantage of its complicated XML API, equipped with a 400+ page PDF manual.
EBay, on the other hand, built a REST API, and has shown the world just how lucrative an accessible API can be. Seeing what Salesforce was up to, eBay jumped on the opportunity to give select partners access to its relatively easy-to-use API, equipped with thorough online documentation.
When eBay first launched its API, the Wall Street Journal wrote : “EBay's new technology—with the decidedly uncatchy name of eBay API (for eBay application programming interface)—reflects the company's growing belief that it can get a piece of e-commerce beyond the confines of its popular online trading post at eBay.com.” EBay's market was no longer limited to the people coming to its website. It extended to any site that could access their API.
The value of extending an e-commerce product offering to other sites is obvious—more opportunities to sell their stuff. And because the implementation of their API was simple and according to the RESTful standard, lots of sites were quick to jump on the opportunity. After all, it enabled them to expand the product offering to their own customers.
It didn't take long for Amazon to follow in eBay's footsteps.
Most importantly, these e-commerce giants nudged other online platforms to start thinking about the value of their code, not just their consumer-facing product.
Flickr Broadens the Horizon
Flickr launched its own REST API in August of 2004, just in time for the rise of social networking and blogging. They quickly became the go-to platform for images, which bloggers were finally able to easily embed on their sites and social media feeds.
[Flickr's site in late 2004 advertises the option to “post to any blog” and share.]
Flickr set the stage for social sharing by offering services that extended past its platform. You could take advantage of the functionality within and outside of the domain. So when Facebook launched later that year, and Twitter followed two years later, internet-savvy folks weren't happy that the platforms didn't have publicly-accessible APIs. Developers were quick to scrape the sites and create Frankenstein APIs. Both sites caved and released official versions of their APIs in 2006.
As the demand for public APIs shot up, the state of the web began to change.
Devs started building web applications on top of existing code. Easily-accessible REST APIs enabled sites to add a functionality to their site in practically no time. In 2006, Amazon Web Services(AWS) helped launch the cloud, and developers were able to access a ton of data space in minutes through AWS' REST API.
The pervasiveness of REST APIs led to what Flickr co-founder Caterina Fake labeled a Web 2.0 world . She said that “while a Web 1.0 world makes partnerships and integration challenging, the Web 2.0 world has the advantage of the API, something that removes many of the bureaucratic, legal, and technical obstacles.” Flickr's open REST API, for example, wasn't just used by lone bloggers and site builders—it was used as marketing for Flickr as a platform.
The API Economy and Beyond
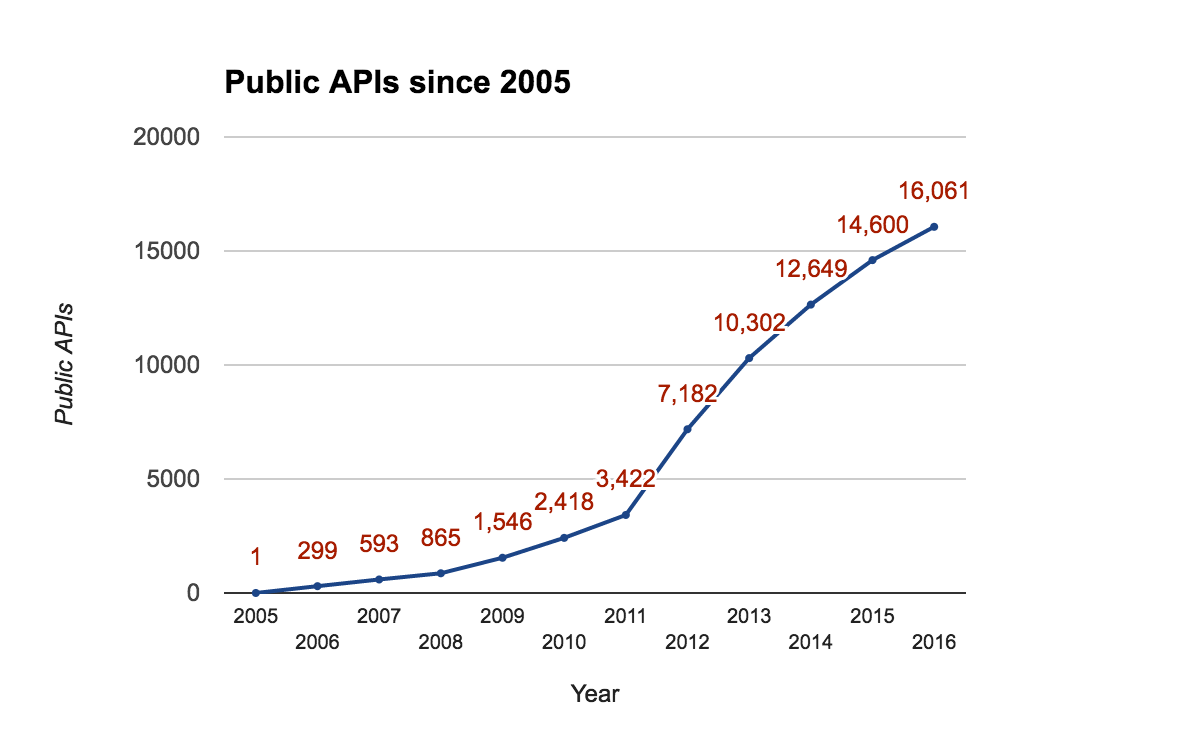
Since 2006, the environment for REST APIs has drastically improved. Developers now know the value of creating an API that's accessible by design. That's why the amount of publicly available APIs built has grown more than 50-fold in the last ten years.
REST APIs are the backbone of the internet and as such powerful drivers, create huge new business opportunities. Where a website could only reach a small portion of your audience, a web API can extend a brand's reach far beyond what the original designers even envision.
Today, APIs aren't just a development technique. The creation of REST as a standard has led APIs to be used by far more people to accomplish far greater undertakings. They're often a core part of software companies' business models, and, as of recently, can be the product itself .
Whether you're embedding photos, tweeting, or storing five terabytes of data on the cloud, you're constantly taking advantage of a landscape made possible by RESTful APIs.
For the end user, this means life is constantly getting easier. It's easier to share documents at work, look up directions, call a taxi, and find old friends. For the developer, it means the sky's the limit. Thanks to the evolution of REST APIs, we don't need a team of engineers or thousand-dollar servers to build software anymore. As long as you can get an API key and access to documentation, you can integrate a functionality into your software.
Now just imagine how much could be possible if we could nail down a documentation standard.
Recommended next reads...
How to engage your api users.
- ReadMe Journey
Why We Work From Home
Stay in-touch.
Want to hear from us about APIs, documentation, DX and what's new at ReadMe?
- IEEE CS Standards
- Career Center
- Subscribe to Newsletter
- IEEE Standards
- For Industry Professionals
- For Students
- Launch a New Career
- Membership FAQ
- Membership FAQs
- Membership Grades
- Special Circumstances
- Discounts & Payments
- Distinguished Contributor Recognition
- Grant Programs
- Find a Local Chapter
- Find a Distinguished Visitor
- Find a Speaker on Early Career Topics
- Technical Communities
- Collabratec (Discussion Forum)
- Start a Chapter
- My Subscriptions
- My Referrals
- Computer Magazine
- ComputingEdge Magazine
- Let us help make your event a success. EXPLORE PLANNING SERVICES
- Events Calendar
- Calls for Papers
- Conference Proceedings
- Conference Highlights
- Top 2024 Conferences
- Conference Sponsorship Options
- Conference Planning Services
- Conference Organizer Resources
- Virtual Conference Guide
- Get a Quote
- CPS Dashboard
- CPS Author FAQ
- CPS Organizer FAQ
- Find the latest in advanced computing research. VISIT THE DIGITAL LIBRARY
- Open Access
- Tech News Blog
- Author Guidelines
- Reviewer Information
- Guest Editor Information
- Editor Information
- Editor-in-Chief Information
- Volunteer Opportunities
- Video Library
- Member Benefits
- Institutional Library Subscriptions
- Advertising and Sponsorship
- Code of Ethics
- Educational Webinars
- Online Education
- Certifications
- Industry Webinars & Whitepapers
- Research Reports
- Bodies of Knowledge
- CS for Industry Professionals
- Resource Library
- Newsletters
- Women in Computing
- Digital Library Access
- Organize a Conference
- Run a Publication
- Become a Distinguished Speaker
- Participate in Standards Activities
- Peer Review Content
- Author Resources
- Publish Open Access
- Society Leadership
- Boards & Committees
- Local Chapters
- Governance Resources
- Conference Publishing Services
- Chapter Resources
- About the Board of Governors
- Board of Governors Members
- Diversity & Inclusion
- Open Volunteer Opportunities
- Award Recipients
- Student Scholarships & Awards
- Nominate an Election Candidate
- Nominate a Colleague
- Corporate Partnerships
- Conference Sponsorships & Exhibits
- Advertising
- Recruitment
- Publications
- Education & Career
Roy T. Fielding: Understanding the REST Style
In this episode.
Roy T. Fielding reminisces about his PhD dissertation, which defined the Representational State Transfer architectural style.
From Computer’s Issue 6, Vol 48 – June 2015

Charles Severance is a clinical associate professor and teaches in the School of Information at the University of Michigan, and served as Computer ‘s multimedia editor until 2018. Follow him on Twitter @drchuck or contact him at [email protected] .
Recommended by IEEE Computer Society

Resurrecting the CDC 6500 Supercomputer
Bruce schneier: the security mindset, the living computer museum, bruce schneier building cryptographic systems, anant agarwal: inside edx, anil jain: 25 years of biometric recognition, john resig: building jquery.
REST API Tutorial
What is REST?
REST is an acronym for REpresentational State Transfer and an architectural style for distributed hypermedia systems. Roy Fielding first presented it in 2000 in his famous dissertation. Since then it has become one of the most widely used approaches for building web-based APIs (Application Programming Interfaces). REST is not a protocol or a …
Written by: Lokesh Gupta
Last Updated: December 12, 2023

REST is an acronym for RE presentational S tate T ransfer and an architectural style for distributed hypermedia systems . Roy Fielding first presented it in 2000 in his famous dissertation . Since then it has become one of the most widely used approaches for building web-based APIs ( Application Programming Interfaces ).
REST is not a protocol or a standard, it is an architectural style. During the development phase, API developers can implement REST in a variety of ways.
Like the other architectural styles, REST also has its guiding principles and constraints. These principles must be satisfied if a service interface has to be referred to as RESTful .
A Web API (or Web Service) conforming to the REST architectural style is called a REST API (or RESTful API ).
1. The Six Guiding Principles of REST
REST is based on some constraints and principles that promote simplicity, scalability, and statelessness in the design. The six guiding principles or constraints of the RESTful architecture are:

1.1. Uniform Interface
By applying the principle of generality to the components interface, we can simplify the overall system architecture and improve the visibility of interactions. Multiple architectural constraints help in obtaining a uniform interface and guiding the behavior of components.
The following four constraints can achieve a uniform REST interface:
- Identification of resources – The interface must uniquely identify each resource involved in the interaction between the client and the server.
- Manipulation of resources through representations – The resources should have uniform representations in the server response. API consumers should use these representations to modify the resource state in the server.
- Self-descriptive messages – Each resource representation should carry enough information to describe how to process the message. It should also provide information of the additional actions that the client can perform on the resource.
- Hypermedia as the engine of application state – The client should have only the initial URI of the application. The client application should dynamically drive all other resources and interactions with the use of hyperlinks.
In simpler words, REST defines a consistent and uniform interface for interactions between clients and servers. For example, the HTTP-based REST APIs make use of the standard HTTP methods (GET, POST, PUT, DELETE, etc.) and the URIs (Uniform Resource Identifiers) to identify resources.
1.2. Client-Server
The client-server design pattern enforces the separation of concerns , which helps the client and the server components evolve independently.
By separating the user interface concerns (client) from the data storage concerns (server), we improve the portability of the user interface across multiple platforms and improve scalability by simplifying the server components.
While the client and the server evolve, we have to make sure that the interface/contract between the client and the server does not break.
1.3. Stateless
Statelessness mandates that each request from the client to the server must contain all of the information necessary to understand and complete the request.
The server cannot take advantage of any previously stored context information on the server.
For this reason, the client application must entirely keep the session state.
1.4. Cacheable
The cacheable constraint requires that a response should implicitly or explicitly label itself as cacheable or non-cacheable.
If the response is cacheable, the client application gets the right to reuse the response data later for equivalent requests and a specified period.
1.5. Layered System
The layered system style allows an architecture to be composed of hierarchical layers by constraining component behavior. In a layered system, each component cannot see beyond the immediate layer they are interacting with.
A layman’s example of a layered system is the MVC pattern . The MVC pattern allows for a clear separation of concerns, making it easier to develop, maintain, and scale the application.
1.6. Code on Demand ( Optional )
REST also allows client functionality to extend by downloading and executing code in the form of applets or scripts.
The downloaded code simplifies clients by reducing the number of features required to be pre-implemented. Servers can provide part of features delivered to the client in the form of code, and the client only needs to execute the code.
2. What is a Resource?
The key abstraction of information in REST is a resource . Any information that we can name can be a resource. For example, a REST resource can be a document or image, a temporal service, a collection of other resources, or a non-virtual object (e.g., a person).
The state of the resource, at any particular time, is known as the resource representation . The resource representations consist of:
- the data
- the metadata describing the data
- and the hypermedia links that can help the clients transition to the next desired state.
A REST API consists of an assembly of interlinked resources. This set of resources is known as the REST API’s resource model .
2.1. Resource Identifiers
REST uses resource identifiers to identify each resource involved in the interactions between the client and the server components.
2.2. Hypermedia
The data format of a representation is known as a media type . The media type identifies a specification that defines how a representation is to be processed.
A RESTful API looks like hypertext . Every addressable unit of information carries an address, either explicitly (e.g., link and id attributes) or implicitly (e.g., derived from the media type definition and representation structure).
Hypertext (or hypermedia) means the simultaneous presentation of information and controls such that the information becomes the affordance through which the user (or automaton) obtains choices and selects actions. Remember that hypertext does not need to be HTML (or XML or JSON) on a browser. Machines can follow links when they understand the data format and relationship types. — Roy Fielding
2.3. Self-Descriptive
Further, resource representations shall be self-descriptive : the client does not need to know if a resource is an employee or a device. It should act based on the media type associated with the resource.
So in practice, we will create lots of custom media types – usually one media type associated with one resource.
Every media type defines a default processing model. For example, HTML defines a rendering process for hypertext and the browser behavior around each element.
Media Types have no relation to the resource methods GET/PUT/POST/DELETE/… other than the fact that some media type elements will define a process model that goes like “anchor elements with an href attribute create a hypertext link that, when selected, invokes a retrieval request (GET) on the URI corresponding to the CDATA -encoded href attribute.”
2.4. Example
Consider the following REST resource that represents a blog post with links to related resources in an HTTP-based REST API. This has the necessary information about the blog post, as well as the hypermedia links to the related resources such as author and comments. Clients can follow these links to discover additional information or perform actions.
3. Resource Methods
Another important thing associated with REST is resource methods . These resource methods are used to perform the desired transition between two states of any resource.
A large number of people wrongly relate resource methods to HTTP methods (i.e., GET/PUT/POST/DELETE). Roy Fielding has never mentioned any recommendation around which method to use in which condition. All he emphasizes is that it should be a uniform interface .
For example, if we decide that the application APIs will use HTTP POST for updating a resource – rather than most people recommend HTTP PUT – it’s all right. Still, the application interface will be RESTful.
Ideally, everything needed to transition the resource state shall be part of the resource representation – including all the supported methods and what form they will leave the representation.
We should enter a REST API with no prior knowledge beyond the initial URI (a bookmark) and a set of standardized media types appropriate for the intended audience (i.e., expected to be understood by any client that might use the API). From that point on, all application state transitions must be driven by the client selection of server-provided choices present in the received representations or implied by the user’s manipulation of those representations. The transitions may be determined (or limited by) the client’s knowledge of media types and resource communication mechanisms, both of which may be improved on the fly (e.g., code-on-demand ). [Failure here implies that out-of-band information is driving interaction instead of hypertext.]
4. REST and HTTP are Not the Same
Many people prefer to compare HTTP with REST. REST and HTTP are not the same.
REST != HTTP
Though REST also intends to make the web (internet) more streamlined and standard, Roy Fielding advocates using REST principles more strictly. And that’s where people try to start comparing REST with the web.
Roy Fielding, in his dissertation, has nowhere mentioned any implementation direction – including any protocol preference or even HTTP. Till the time, we are honoring the six guiding principles of REST, which we can call our interface – RESTful.
In simple words, in the REST architectural style, data and functionality are considered resources and are accessed using Uniform Resource Identifiers (URIs).
The resources are acted upon by using a set of simple, well-defined operations. Also, the resources have to be decoupled from their representation so that clients can access the content in various formats, such as HTML, XML, plain text, PDF, JPEG, JSON, and others.
The clients and servers exchange representations of resources by using a standardized interface and protocol. Typically HTTP is the most used protocol, but REST does not mandate it.
Metadata about the resource is made available and used to control caching, detect transmission errors, negotiate the appropriate representation format, and perform authentication or access control.
And most importantly, every interaction with the server must be stateless.
All these principles help RESTful applications to be simple, lightweight, and fast.
Happy Learning !!
References:
- REST APIs must be hypertext-driven
- REST Arch Style

About Lokesh Gupta
Thu 20 May 2010
ICSE Most Influential Paper award
Posted by Roy T. Fielding under open source , software architecture , web architecture [5] Comments
On the same day that Liam was born , I received news that one of my two papers published at the ICSE 2000 conference has been given the International Conference on Software Engineering’s Most Influential Paper Award for its impact on software engineering research over the past decade. The paper, A case study of open source software development: the Apache server , is co-authored by Audris Mockus, myself, and James Herbsleb. The MIP is an important award within the academic world; my thanks to the award committee and congrats to Audris and Jim. I wish I could have been there in South Africa for the presentation. This year’s award is shared with a paper by Corbett et al. on Bandera .
Interestingly, my other paper in ICSE 2000 was the first conference paper about REST , co-authored with my adviser, Dick Taylor . That must have caused some debate within the awards committee. As I understand it, the MIP award is based on academic citations of the original paper and any follow-up publication in a journal. Since I encouraged people to read and cite my dissertation directly, rather than the ICSE paper’s summary or its corresponding journal version , I am not surprised that the REST paper is considered less influential. However, it does make we wonder what would have happened if I had never published my dissertation on the Web. Would that paper have been cited more, or would nobody know about REST? shrug . I like the way it turned out.
The next two International Conferences on Software Engineering will be held in Hawaii ( ICSE 2011 ), with Dick as the general chair, and Zürich ( ICSE 2012 ). That is some fine scheduling on the part of the conference organizers! Fortunately, I have a pretty good excuse to attend both.
Tags: Apache , ICSE , MIP , REST
Sun 16 May 2010
Some people call him Liam
Posted by Roy T. Fielding under Family [13] Comments

Three weeks early. Twenty-two days early, to be exact. All the books say that the range of 38-42 weeks is “normal”, so he was only eight days ahead of the curve and (thank goodness) beyond the stage of preemie health concerns. 2600 grams (5.732 lbs.) of joy, and a healthy Mommy as well. Woohoo! Of course, that also meant we were tossed out of the hospital about 40 hours after birth, thanks to our wonderful US healthcare system.

Twenty-two days early doesn’t sound like much, but it is huge. Most of our friends went long for their first baby, so I had this schedule in the back of my mind of all the things that I was going to finish by April so that I could take a long, relaxing break into parenthood. Bzzt! The Anaheim IETF meeting was being held the following week, just twelve miles from my house, and my fellow HTTP standard editors had planned a whole week of editing httpbis at or near my place. Bzzt! We had delayed buying a bunch of baby things until after the shower. Bzzt! We had all these classes on what to expect in terms of sensing the arrival and onset of labor. Bzzt!

I’ll be catching up on the backblog soon. Now, if I can just get him to sleep long enough to edit a specification …
BTW, Liam is his nickname.
Tags: fatherhood
Wed 13 May 2009
Wrangling mime.types
Posted by Roy T. Fielding under open source , standards , web architecture [13] Comments
One of the chores that I do for the Apache HTTP server project , every three months or so, is to slog through the IANA media type registry to see what new media types have been registered and add them to the mime.types configuration file. This is one of the few things I do that is almost all pain for little or no gain. It takes hours to do it right because IANA has gone out of their way to make the registry impossible to process automatically via simple scripts. I don’t even get the pleasure of “changing the world” in some meaningful way, since Apache doesn’t update mime.types automatically when installed to an existing configuration.
BTW, if you are responsible for an existing Apache installation, please copy the current mime.types configuration file and install it manually — your users will thank you later not gripe as much about unsupported media types.
IANA is a quaint off-shoot of the Internet Engineering Taskforce that, much like the IETF, is still stuck in the 1980s. One would think that, given a task like “maintain a registry of all media types” so that Internet software can communicate, would lead to something that is comprehensible by software. Instead, what IANA has provided is a collection of FTP directories containing a subset of private registry templates, each in the original (random) submitted format, and nine separate inconsistently-formated index.html files that actually contain the registered types.
The first thought that any Web developer has when they look at the registry is that it should be laid out as a resource space by type. That is, each directory under “media-types” would be a major type (e.g., application , text , etc.) and then each file within those directories would correspond to exactly one subtype (e.g., html , plain , csv , etc.). Such a design would be easy to process automatically and fits with the organization’s desire to serve everything via both FTP and HTTP. Sadly, that is not the case. Most of the private registrations have some sort of like-named file within the expected directory to contain its registration template, but the names do not always correspond exactly to the subtype and the contents are whatever random text was submitted (rather than some consistent format that could be extracted). What’s worse, however, is that the standardized types do not have any corresponding file; instead, the type’s entry in the index may have some sort of link to the RFC or external specification that defines that type.
The second thought of any Web developer would be “oh, I’ll just have to process the index files to extract the media type fields.” Good luck. The HTML is not well-formed (even by HTML standards). It uses arbitrarily-created tables to contain the actual registry information. There is no consistency across the files in terms of the number of table columns, nor any column headers to indicate what they mean. There is no mark-up to distinguish the registry cells from other whitespace-arranging layout cells. And the registered types are occasionally wrapped in inconsistently-targeted anchors for links to the aforementioned template files.
grumble GRUMBLE
Okay, so the really stubborn Web developers think that maybe a browser can grok this tag soup and generate the table in some reasonably consistent fashion, which can then be screen-scraped to get the relevant information. Nope. It doesn’t even render the same on different browsers. In any case, the index files don’t contain the relevant information: the most important information (aside from the type name) is the unique filename extension(s) that are supposed to be used for files of that type. For that information, we have to follow the link to the registry template file, or RFC containing one or more template files, and look for the optional form field for indicating extensions. Most of the time, the field is empty or just plain wrong (i.e., almost all XML-based formats suggest that the filename extension is .xml, in spite of the fact that the only reason to supply an extension is so that all files of that extension can be mapped to that specific type).
And, perhaps the most annoying thing of all: the index files are obviously being generated from some other data source that is not part of the public registry.
Normally, what I am left with is a semi-manual procedure. I keep a mirror of the registry files on my laptop and, each time I need to do an update, I pull down a new mirror and run a diff between the old and new index files. I then manually look-up the registry template for file extensions or, if that fails, do a web search for what the deployed software already does. I then do a larger Web search for documentation that various companies have published about their unregistered file types, since I’ve given up on the idea that companies like Adobe, Microsoft, and Sun will ever register their own types before deploying some half-baked experimental names that we are stuck with forever due to backwards-compatibility concerns.
Unfortunately, yesterday I messed up that normal procedure. I forgot that I had started to do the update a month ago by pulling down a new mirror, but hadn’t made the changes yet. So I blew away my last-update-point before doing the diff.
After reliving all of the above steps, I ended up with a new semi-manual procedure:
That gave me a list of new registered types that were not already present in mime.types. I still had to go through the list manually, add each type to its location within mime.types, and search for its corresponding file extension within the registry templates. As usual, most of the types either had no file extension (typical for types that are only expected to be used within message envelopes) or non-unique extensions that can’t be added to the configuration file because they would override some other (more common) type.
Please, IANA folks, fix your registries so that they can be read by automated processes. Do not tell me that I have to write an RFC to specify how you store the registry files. The existing mess was not determined by an RFC, so you are free to fix it without a new RFC. If you have software generating the current registry, then I will be more than happy to fix it for you if you provide me with the source code. At the very least, include a text/csv export of whatever database you are using to construct the awful index files within the current registry.
Why am I bothering with all this? Because media types are the only means we have for an HTTP sender to express the intent for processing a given message payload . While some people have claimed that recipients should sniff the data format for type information, the fact is that all data formats correspond to multiple media types. Sniffing a media type is therefore inherently impossible: at best, it can indicate when a data format does not match the indicated media type; at worst, it breaks correct configurations and creates security holes. In any case, sniffing cannot determine the sender’s intent.
The intent can only be expressed by sending the right Content-Type for a given resource. The resource owner needs to configure their resource correctly. Even though Apache provides at least five different ways to set the media type, most authors still rely on the installed file extension mappings for representations that are not dynamically-generated. Hence, most will rely on whatever mime.types file has been installed by their webmaster, even if it hasn’t been updated in ten years.
How old is your mime.types file?
Tags: media types , mime.types
Fri 20 Mar 2009
It is okay to use POST
Posted by Roy T. Fielding under software architecture , web architecture [12] Comments
Tim Bray’s article on RESTful Casuistry revisits an odd meme in the REST debates that I’ve been meaning to discredit for a while.
Some people think that REST suggests not to use POST for updates. Search my dissertation and you won’t find any mention of CRUD or POST. The only mention of PUT is in regard to HTTP’s lack of write-back caching. The main reason for my lack of specificity is because the methods defined by HTTP are part of the Web’s architecture definition, not the REST architectural style. Specific method definitions (aside from the retrieval:resource duality of GET) simply don’t matter to the REST architectural style, so it is difficult to have a style discussion about them. The only thing REST requires of methods is that they be uniformly defined for all resources (i.e., so that intermediaries don’t have to know the resource type in order to understand the meaning of the request). As long as the method is being used according to its own definition, REST doesn’t have much to say about it.
For example, it isn’t RESTful to use GET to perform unsafe operations because that would violate the definition of the GET method in HTTP, which would in turn mislead intermediaries and spiders. It isn’t RESTful to use POST for information retrieval when that information corresponds to a potential resource, because that usage prevents safe reusability and the network-effect of having a URI. But why shouldn’t you use POST to perform an update? Hypertext can tell the client which method to use when the action being taken is unsafe. PUT is necessary when there is no hypertext telling the client what to do, but lacking hypertext isn’t particularly RESTful.
POST only becomes an issue when it is used in a situation for which some other method is ideally suited: e.g., retrieval of information that should be a representation of some resource (GET), complete replacement of a representation (PUT), or any of the other standardized methods that tell intermediaries something more valuable than “this may change something.” The other methods are more valuable to intermediaries because they say something about how failures can be automatically handled and how intermediate caches can optimize their behavior. POST does not have those characteristics, but that doesn’t mean we can live without it. POST serves many useful purposes in HTTP, including the general purpose of “this action isn’t worth standardizing.”
I think the anti-POST meme got started because of all the arguments against tunneling other protocols via HTTP’s POST (e.g., SOAP, RSS, IPP, etc.). Somewhere along the line people started equating the REST arguments of “don’t violate HTTP’s method definitions” and “always use GET for retrieval because that forces the resource to have a URI” with the paper tiger of “POST is bad.”
Please, let’s move on. We don’t need to use PUT for every state change in HTTP. REST has never said that we should.
What matters is that every important resource have a URI, therein allowing representations of that resource to be obtained using GET. If the deployment state is an important resource, then I would expect it to have states for undeployed , deployment requested , deployed , and undeployment requested . The advantage of those states is that other clients looking at the resource at the same time would be properly informed, which is just good design for UI feedback. However, I doubt that Tim’s application would consider that an important resource on its own, since the deployment state in isolation (separate from the thing being deployed) is not a very interesting or reusable resource.
Personally, I would just use POST for that button. The API can compensate for the use of POST by responding with the statement that the client should refresh its representation of the larger resource state. In other words, I would return a 303 response that redirected back to the VM status, so that the client would know that the state has changed.
Fri 24 Oct 2008
Specialization
Posted by Roy T. Fielding under blogging , software architecture , systems engineering , web architecture [6] Comments
As you may have noted, my last post seems to have hit a nerve in various communities, particularly with those who are convinced that REST means HTTP (because, well, that’s what they think it means) and that any attempt by me to describe REST with precision is just another elitist philosophical effort that won’t apply to those practical web developers who are just trying to get their javascript to work on more than one browser.
Apparently, I use words with too many syllables when comparing design trade-offs for network-based applications. I use too many general concepts, like hypertext, to describe REST instead of sticking to a concrete example, like HTML. I am supposed to tell them what they need to do, not how to think of the problem space. A few people even complained that my dissertation is too hard to read. Imagine that!
My dissertation is written to a certain audience: experts in the fields of software engineering and network protocol design. These are folks with long industry careers or graduate degrees, usually Ph.D.s who have spent decades learning about their field, identifying an untrodden path to pursue advanced research, and eventually becoming so familiar with that path that they are (hopefully) able to learn something that nobody else in the world has revealed before. In the process, they become specialists , because it is only through specialization that a human being can become sufficiently knowledgeable to find what has yet to be known in a field as large as computing. It is only by becoming specialists that we can understand each other when we explain what we have learned, and thereby grow the field of knowledge over time.
James Burke described the problem of specialization in the final episode of his first series on BBC, Connections . If you are having a hard time following my work, then I strongly suggest you go find a copy of the old episodes somewhere and watch them, bearing in mind that it was first broadcast in 1978, when the folks who brought you the Web were at their most impressionable early age. Mr. Burke would appreciate that connection, I think. What he said deserves a bit of transcripting on my part:
The other, general thing to be said about how change comes about through innovation, and especially about the rate in which that change occurs, is that: the easier you can communicate, the faster change happens . I mean, if you look back at the past, in that light, you’ll see that there was a great surge in invention in the European Middle Ages, as soon as they had reestablished safe communication between their cities, after the so-called dark ages. There was another one, in the sixteenth century, when these [books] gave scientists and engineers the opportunity to share their knowledge with each other, thanks to a German goldsmith called Johannes Gutenberg who’d invented printing back in the 1450s. And then, when that developed out there, telecommunications, oh a hundred-odd years ago, then things really started to move. It was with that second surge, in the sixteenth century, that we moved into the era of specialization: people writing about technical subjects in a way that only other scientists would understand. And, as their knowledge grew, so did their need for specialist words to describe that knowledge. If there is a gulf today, between the man-in-the-street and the scientists and the technologists who change his world every day, that’s where it comes from. It was inevitable. Everyday language was inadequate. I mean, you’re a doctor. How do you operate on somebody when the best description of his condition you have is “a funny feeling in the stomach?” The medical profession talks mumbo jumbo because it needs to be exact. Or would you rather be dead? And that’s only a very obvious example. Trouble is, when I’m being cured of something, I don’t care if I don’t understand. But what happens when I do care? When, say, the people we vote for are making decisions that effect our lives deeply, `cause that is, after all, when we get our say, isn’t it? When we vote? But say the issue relates to a bit of science and technology we don’t understand? Like, how safe is a reactor somebody wants to build? Or, should we make supersonic airplanes? Then, in the absence of knowledge, what is there to appeal to except our emotions? And then the issue becomes “national prestige,” or “good for jobs,” or “defense of our way of life,” or something. And suddenly you’re not voting for the real issue at all. [James Burke, “Yesterday, Tomorrow and You” (19:02-21:30), 1978]
Still timely after all these years, isn’t it?
As scientists go, I am a generalist: the topics that I care about range from international politics to physics, with most applications of computing somewhere in between. However, when I send out a message to API designers , I expect the audience to be reasonably competent in the field. I have to talk to them as a specialist because I want them to understand, as specialists themselves, exactly what I am trying to convey and not some second-order derivatives. Most of the terms that I use should already be familiar to them (and thus it is a waste of everyone’s time for me to define them). When there is a concern about a particular term, like hypertext , it can be resolved by pointing out the relevant definitions that I use as an expert in the field.
I don’t try to tell them exactly what to do because, quite frankly, I don’t have anywhere near enough knowledge of their specific context to make such a decision. What I can do is tell them what isn’t REST or that doesn’t fit my definitions, because that is something about which I am guaranteed to know more than anyone else on this planet. That’s what happens when you complete a dissertation on a topic.
So, when you find it hard to understand what I have written, please don’t think of it as talking above your head or just too philosophical to be worth your time. I am writing this way because I think the subject deserves a particular form of precision. Instead, take the time to look up the terms. Think of it as an opportunity to learn something new, not because I said so, but because it will do you some personal good to better understand the depth of our field. Not just the details of what I wrote, but the background knowledge implied by all the strange terms that I used to write it.
Others will try to decipher what I have written in ways that are more direct or applicable to some practical concern of today . I probably won’t, because I am too busy grappling with the next topic, preparing for a conference, writing another standard, traveling to some distant place, or just doing the little things that let me feel I have I earned my paycheck. I am in a permanent state of not enough time. Fortunately, there are more than enough people who are specialist enough to understand what I have written (even when they disagree with it) and care enough about the subject to explain it to others in more concrete terms, provide consulting if you really need it, or just hang out and metablog. That’s a good thing, because it helps refine my knowledge of the field as well.
We are communicating really, really fast these days. Don’t pretend that you can keep up with this field while waiting for others to explain it to you.
Tags: Connections , James Burke , precision , REST , specialization
Mon 20 Oct 2008
REST APIs must be hypertext-driven
Posted by Roy T. Fielding under software architecture , web architecture [51] Comments
I am getting frustrated by the number of people calling any HTTP-based interface a REST API. Today’s example is the SocialSite REST API . That is RPC. It screams RPC. There is so much coupling on display that it should be given an X rating.
What needs to be done to make the REST architectural style clear on the notion that hypertext is a constraint? In other words, if the engine of application state (and hence the API) is not being driven by hypertext, then it cannot be RESTful and cannot be a REST API. Period. Is there some broken manual somewhere that needs to be fixed?
API designers, please note the following rules before calling your creation a REST API:
- A REST API should not be dependent on any single communication protocol, though its successful mapping to a given protocol may be dependent on the availability of metadata, choice of methods, etc. In general, any protocol element that uses a URI for identification must allow any URI scheme to be used for the sake of that identification. [Failure here implies that identification is not separated from interaction.]
- A REST API should not contain any changes to the communication protocols aside from filling-out or fixing the details of underspecified bits of standard protocols, such as HTTP’s PATCH method or Link header field. Workarounds for broken implementations (such as those browsers stupid enough to believe that HTML defines HTTP’s method set) should be defined separately, or at least in appendices, with an expectation that the workaround will eventually be obsolete. [Failure here implies that the resource interfaces are object-specific, not generic.]
- A REST API should spend almost all of its descriptive effort in defining the media type(s) used for representing resources and driving application state, or in defining extended relation names and/or hypertext-enabled mark-up for existing standard media types. Any effort spent describing what methods to use on what URIs of interest should be entirely defined within the scope of the processing rules for a media type (and, in most cases, already defined by existing media types). [Failure here implies that out-of-band information is driving interaction instead of hypertext.]
- A REST API must not define fixed resource names or hierarchies (an obvious coupling of client and server). Servers must have the freedom to control their own namespace. Instead, allow servers to instruct clients on how to construct appropriate URIs, such as is done in HTML forms and URI templates, by defining those instructions within media types and link relations. [Failure here implies that clients are assuming a resource structure due to out-of band information, such as a domain-specific standard, which is the data-oriented equivalent to RPC’s functional coupling].
- A REST API should never have “typed” resources that are significant to the client. Specification authors may use resource types for describing server implementation behind the interface, but those types must be irrelevant and invisible to the client. The only types that are significant to a client are the current representation’s media type and standardized relation names. [ditto]
- A REST API should be entered with no prior knowledge beyond the initial URI (bookmark) and set of standardized media types that are appropriate for the intended audience (i.e., expected to be understood by any client that might use the API). From that point on, all application state transitions must be driven by client selection of server-provided choices that are present in the received representations or implied by the user’s manipulation of those representations. The transitions may be determined (or limited by) the client’s knowledge of media types and resource communication mechanisms, both of which may be improved on-the-fly (e.g., code-on-demand). [Failure here implies that out-of-band information is driving interaction instead of hypertext.]
There are probably other rules that I am forgetting, but the above are the rules related to the hypertext constraint that are most often violated within so-called REST APIs. Please try to adhere to them or choose some other buzzword for your API.
Tags: hypertext , REST
Mon 29 Sep 2008
No REST in CMIS
Posted by Roy T. Fielding under standards , web architecture [10] Comments
About three weeks ago, a new “standard” for Content Management Interoperability Services (CMIS) was announced by EMC, IBM, and Microsoft with the usual fanfare of being the best thing since sliced bread and compliant with the latest buzzwords. One of those buzzwords, REST (as in Representational State Transfer), happens to be defined by my dissertation . I am getting tired of big companies making idiotic claims about REST and their so-called RESTful architectures. The only similarity between CMIS and REST is that they both have four-letter acronyms.
Note to our technology industry rags: A standard is an approved measure against which multiple independent organizations have agreed (by choice or by force) to have their products tested for compliance. A standards-effort is what we call a proposal when it is being actively worked on by some standards development organization. CMIS, on the other hand, is just a vendor proposal that is being submitted to OASIS . It only becomes a standards-effort once the OASIS members agree to host it, which shouldn’t be a problem given the pay-to-play nature of OASIS, and might become a standard if the final specification is approved .
CMIS is a thin veneer on RDBMS-based data repositories that provides a data model for document-like objects within filesystem-like folders, basic file versioning, and access via SQL queries and local object references. It is exactly the kind of document model one would expect within a legacy document management system that is backed by a large relational database and authored via Microsoft Office applications. No surprise, given the sponsors, and there are plenty of good reasons why folks would want to support such data models. For the interface, CMIS includes both a Web Services SOAP/WSDL protocol binding , tightly coupled to the data model, and a REST protocol binding , which also happens to be tightly coupled to the data model.
REST is an architectural style, not a protocol, and thus announcing it as a protocol binding is absurdly ignorant behavior for a group of technology companies. The RESTish protocol binding actually being proposed by CMIS is AtomPub , or at least it would be if not for the huge number of unnecessary protocol extensions that tunnel the Web Services interface through fake-Atom and fake-HTTP. The examples assume a single-script gateway that accepts methods in query strings with CMIS-* header fields to bind search scope, just like SOAP envelopes and bodies are used to tunnel object-specific protocols over HTTP. Are there any REST constraints that this binding doesn’t violate?
The SOAP protocol binding, in contrast, is more direct: half the number of pages and defined with WSDL and XSD. It is obvious that the SOAP binding was designed first and the AtomPub binding added for marketing reasons. I don’t think much of SOAP bindings, in general, but at least this one is consistent with the limited data model, the design of other SOAP-based services, and the goal of providing a control-oriented API for document management.
CMIS is a classic example of what happens when a control-oriented interface is slapped onto an HTTP-based protocol instead of redesigning the interface to be data-oriented. All of the lowest-common-denominator constraints of CMIS’ data model, which are necessary for the SOAP interface because its operations are object-specific, are completely unnecessary for an HTTP interface that is properly designed to be data-oriented. An HTTP interface doesn’t need to be limited to Atom feed formats for traversing folder hierarchies; hypertext is a lot more powerful than temporally-ordered query results. An HTTP interface doesn’t need to forbid the versioning of folders; hypertext can tell the client what operations are allowed on each folder. An HTTP interface doesn’t need a special query media type that (insanely) consists of a raw SQL statement embedded in XML sugar coating; any HTTP resource can be a stored procedure and any hypertext response can contain a list of results. An HTTP interface doesn’t need to traverse folders or query databases in order to access an object summary that points to a content stream that might then be downloaded; hypertext allows each object to be identified by a URI and manipulated independent of the discovery process.
CMIS is a Web Services interface for document management. It should be renamed WS-DMS and tossed on the same pile of other specs from that genre. WebDAV is a far more capable interface that has already been standardized to provide document-level write-access and versioning over HTTP. WebDAV isn’t very RESTful either, because it relies on folder operations instead of hypertext, but at least the WebDAV interface doesn’t interfere with the read-only side of HTTP, WebDAV is already supported by authoring tools with filesystem semantics, and Microsoft has already deployed hundreds of proprietary extensions to WebDAV within its Exchange and SharePoint server products. For that matter, CMIS would be a lot more interesting if it were designed as an extension to CIFS instead of HTTP or SOAP.
My bet is that the document repository vendors will continue to focus on making their own native HTTP interfaces more efficient, since that is how customers will evaluate their performance when integrated within heterogeneous architectures. At best, CMIS will become another method for data migration away from Web Services and legacy repositories, which may be justification enough for implementation. However, they should stop calling their AtomPub derivative a REST binding. Even if they manage to redesign the HTTP interface during the standards process, it will still only be an HTTP binding and only one part of an overall application architecture that could be called RESTful.
Tags: AtomPub , CMIS , REST , WebDAV
Mon 22 Sep 2008
Economies of scale
Posted by Roy T. Fielding under software architecture , system dynamics , systems engineering , web architecture [2] Comments
I need to address that teaser I included in my last post on paper tigers and hidden dragons :
People need to understand that general-purpose PubSub is not a solution to scalability problems — it simply moves the problem somewhere else, and usually to a place that is inversely supported by the economics.
I am talking here about the economics of sustainable systems, which I consider to be part of System Dynamics and Systems Engineering . Software Architecture and System Dynamics are deeply intertwined, just as Software Engineering and Systems Engineering are deeply intertwined, but they are not the same thing.
Fortunately, this discussion of economics has nothing to do with the financial economy or the proposed bailout on Wall Street. At least, I don’t think it does, though event-based integration and publish-subscribe middleware are most popular within financial institutions (and rightly so, since it matches their natural data stream of buy/sell events and news notifications that drive financial investing/speculation).
Economists have a well-known (but often misunderstood) notion of the economies of scale , which can be summarized as the effect of increased production on the average cost of production (see also Wikipedia and Investopedia ). For most types of business, the average cost of producing some item is expected to go down as the business expands. This is a natural consequence of both the spreading of fixed costs over many more customers and the ability of larger distributors to demand more competitive pricing from their upstream suppliers (e.g., Walmart ).
If we look at such a business in terms of its system dynamics, we should see “load” on the system increase at a much lower rate than the increase in customers. In other words, the additional customers should not, on average, create more cost than they generate in revenue once the business passes the initial fixed infrastructure cost break-even point. If they do create more cost, then the business is not sustainable at larger scales. For many businesses, that’s just fine — most of the personal services economy is based on models with a small window between “enough customers to survive” and “too many customers to handle without degrading service.”
The same is true of software architectures for network-based applications. As the number of consumers increase, the per-consumer cost of the overall system must decrease in order to sustain the system. Relative economies of scale were used by Nikunj Mehta in his dissertation to compare architectural choices: “A system is considered to scale economically if it responds to increased processing requirements with a sub-linear growth in the resources used for processing.” I like that as a quantifiable definition for the architectural property of scalability . However, Nikunj is focused on comparing the relative scalability of particular implementations within an architecture-driven modular framework, not the type of economics that I alluded to in my post.
It is important to think of system dynamics in terms of economics and not just system throughput, since the impact of growth in non-sustainable systems is often unrelated to the individual data transfers or protocols in use. In fact, some architectures that are more efficient from the standpoint of per-event network usage are also more susceptible to inverse economies of scale. PubSub is one such example.
PubSub (short for publish/subscribe) is a derivative of one of the most analyzed architectural styles in software: event-based integration (EBI). From a purely theoretical perspective, event-based integration is a natural fit for systems that monitor real-time activities, particularly when the number of event sources outnumber the recipients of event notifications (e.g, graphical user interfaces and process control systems). However, EBI does not scale well when the number of recipients greatly outnumbers the sources. Researchers have been studying Internet-scale event notification systems for over two decades. Several derivative styles have been proposed to help reduce the issue of scale, including PubSub, EventBus, and flood distribution. There are probably others that I have left out, but they usually boil down into the use of event brokers (intermediaries) and/or a shared data stream (multicast and flood).
PubSub improves EBI scalability by filtering events, either by publisher-driven topics or subscriber-chosen content, and only delivering notifications to the matching subscribers of those topics/content. In theory, if we are careful in choosing the topics such that they partition the events into relatively equal, non-overlapping subsets, and if the consumers of those events are only interested in subscribing to a small subset of those topics, then the corresponding reduction in notification traffic is substantial. Group chat, as in Jabber rooms, is one such example. For most applications, however, such a partitioning does not exist.
EventBus takes a slightly different tack on scalability by forcing traffic onto shared distribution streams, usually IP multicast or flood-distribution channels, and having all subscribers pick their own events off that stream. Unfortunately, multicast does not scale socially (a tragedy of the commons) and rarely succeeds across organizational domains, whereas flooding only succeeds when the signal/noise ratio is high.
Of course, there are many examples of successful EBI systems. USENET news, for example, combined both hierarchical PubSub and flood-distribution to great effect. Adam Rifkin and Rohit Khare did an extensive survey of Internet-scale event notification systems that still stands the test of time. And, as I said at the beginning, EBI is the most popular style of system architecture within the financial industry, where scalability is offset by relatively high subscription costs.
So, what’s the point of this rambling post? Ah, yes, now I remember: the inverse economics of general-purpose PubSub.
People are greedy. They tend to be event-gluttons, wishing to receive far more information than they actually intend to read, and rarely remember to unsubscribe from event streams. When they stop using a service, they tend to remove the software that reports the notifications locally, not the software or subscriptions that cause it to be delivered. If it were not for automatic bounce handling, Apache mailing lists would have melted down years ago. The only way to constrain such users is a tax on either subscriptions or deliveries.
PubSub systems have an imbalance of effort to subscribe versus effort to deliver. In other words, a single user request results in a potentially large number of server obligations. As such, a benevolent user can produce a disproportionate load on the publisher or broker that is distributing notifications. On the Internet, we don’t have the luxury of designing just for benevolent users, and thus in HTTP systems we call such requests a denial-of-service exploit. Any request architecture that allows a malevolent user to create load as a multiple of the effort required to make the request will result in denial of service attacks, since they succeed without overwhelming the attacker’s own connectivity.
The only solution to the inverse economics of PubSub that I know of is to match the costs to the revenue stream. In other words, charge consumers for the subscriptions they choose to receive, at a rate corresponding to the cost of delivering the subscribed stream at the subscribed rate and over the subscribed medium. That is exactly why there is no standard mechanism for notifications in HTTP: there is no scalable solution for subscribing to events without also standardizing the creation of user accounts and event filtering mechanisms, neither of which tend to be standardized because user management is an application of its own and event filtering is always domain-specific.
What does this mean for a system like Jabber ? It means that each jabber server (the broker) needs to keep watch on the types of systems being supported via its infrastructure and adjust their subscription model accordingly. Applications like chat will work great, as will most applications wherein the event sources far outnumber the notification recipients. Applications with inverse economics need to pay their own way.
What does this mean for a system like Twitter ? Well, that’s an interesting case because it incorporates both subscription-based following of events and RESTful interfaces for event logs. When a user only follows a small set of twitters, or the set of twitters being followed are mostly quiet, then they might be more economically supported by an EBI system instead of polling their twitter home stream. However, that won’t be true for people who want to follow many twitters or who are only interested in looking at twits in batch (basically, anyone who polls at a lower frequency than their incoming twit rate). In particular, malevolent followers (those robots that follow everyone, for whatever reason) are much more dangerous to an EBI system.
My guess is that Twitter will eventually move to an ad-supported revenue stream on their Web interfaces, since ad revenue increases at the same rate as RESTful applications need to scale (i.e., RESTful systems have a natural economy of scale that makes them sustainable even when their popularity isn’t anticipated). Likewise, Twitter’s event-based interfaces will move toward a more sustainable subscription model that charges for excessive following and premium services like real-time event delivery via XMPP or SMS. That kind of adjustment is necessary to rebalance the system dynamics.
Tags: economies of scale , jabber , REST , scalability , software architecture , system dynamics , systems engineering , twitter
Wed 3 Sep 2008
Paper tigers and hidden dragons
Posted by Roy T. Fielding under software architecture , web architecture [17] Comments
One of the sessions that I attended at OSCON was “ Beyond REST? Building Data Services with XMPP PubSub †by Evan Henshaw-Plath and Kellan Elliott-McCrea . I think you can guess why that made me curious, but it was interesting to see how much that curiosity was shared by the rest of the conference: the room filled up long before the scheduled start. They certainly gave a very entertaining talk and one that spilled over into the blogosphere in posts by Stephen O’Grady , Joshua Schachter , and Debasish Ghosh .
Unfortunately, the technical argument was a gigantic paper tiger, which is a shame given that there are plenty of situations in which event-based architectures are a better solution than REST-based architectures. I made a brief comment about notification design and how they seemed to be ignoring a good twenty years of research on Internet-scale event notification systems . People need to understand that general-purpose PubSub is not a solution to scalability problems — it simply moves the problem somewhere else, and usually to a place that is inversely supported by the economics. I’ll have to explain that in a later post, since this one is focused on the technical.
Here’s the tiger:
On July 21st, 2008, friendfeed crawled flickr 2.9 million times to get the latest photos of 45,754 users, of which 6,721 of that 45,754 potentially uploaded a photo. Conclusion: Polling sucks.
If you’d like to learn more about their XMPP solution, the slides are available from the OSCON website. I do think there is a lot to be learned from using different interaction styles and true stream-oriented protocols (the kind that don’t care about lost packets), but this FriendFeed example is ridiculous. It took me less than 30 seconds to design a better solution using nothing more than HTTP, and that while sitting in the middle of a conference session. This is exactly what Dare means by: “ If a service doesn’t scale it is more likely due to bad design than to technology choice. ”
They are comparing the efficiency of blind polling using HTTP crawls to a coordinated PubSub services setup with XMPP. Spidering an entire site is obviously not going to be efficient if you are only interested in what has changed. One advantage it has is that you don’t need to cooperate with the information provider. However, for the specific example of FriendFeed polling Flickr, cooperation is easy (both companies gain immensely by cooperating) and essential (2.9 million requests per day will get you blocked from any site that doesn’t want cooperation).
The solution, which I mentioned briefly at the talk, is to provide a resource that reflects all of the changes on Flickr during a given time period. Anyone (not just FriendFeed) can perform a GET on that resource to find out what has changed. In fact, one such example is the SUP (Simple Update Protocol) just introduced by FriendFeed. However, I had something more efficient in mind.
Web architects must understand that resources are just consistent mappings from an identifier to some set of views on server-side state. If one view doesn’t suit your needs, then feel free to create a different resource that provides a better view (for any definition of “better”). These views need not have anything to do with how the information is stored on the server, or even what kind of state it ultimately reflects. It just needs to be understandable (and actionable) by the recipient.
In this case, we want to represent the last-updated state of all Flickr users in a way that minimizes the lag between event and notification (let’s just assume that one minute is “fast enough” to receive a change notification). The simplest way of doing that is to log state changes by userid in a sequence of journal-style resources named according to the server’s UTC clock minutes. For example,
This URI pattern instantly drops the poll count from 2.9 million to 1440 (the number of minutes in a day) plus whatever pages are retrieved after we notice a user has changed their state. Alternatively, we could define a single append-only resource per day and use partial GET requests to retrieve only the bits since the last poll, but that tends to be harder on the server. Representations for the above resources can be generated by non-critical processes, cached, and even served from a separate distribution channel (like SUP).
What, then, should we include in the representation? Well, a simple list of relative URIs is good enough if the pattern is public, but that would be unwise for a site that features limited publication (obscured identifiers so that only people who have been given the URI can find the updated pictures). Likewise, the list might become unwieldy during event storms, when many users happen to publish at once. Of course, like any good CS problem, we can solve that with another layer of indirection.
Instead of a list of changed user ids or URIs, we can represent the state as a sparse bit array corresponding to all of Flickr’s users. I don’t know exactly how many users there are at Flickr, but let’s be generous and estimate it at one million. One million bits seems like a lot, but it is only 122kB in an uncompressed array. Considering that this array will only contain 1s when an update has occurred within the last minute, my guess is that it would average under 1kB per representation.
I can just imagine people reading “sparse bit array” and thinking that I must be talking about some optimal data structure that only chief scientists would think to use on the Web. I’m not. Any black-and-white GIF or PNG image is just a sparse bit array, and they have the nice side-effect of being easy to visualize. We can define our representation of 1 million Flickr users to be a 1000×1000 pixel black-and-white image and use existing tools for its generation (again, something that is easily done outside the critical path by separate programs observing the logs of changes within Flickr). I am quite certain that a site like Flickr can deliver 1kB images all day without impacting their scalability.
Finally, we need a way to map from the bits, each indicating that a user has changed something, to the much smaller set of users that FriendFeed knows about and wishes to receive notifications. If we can assume that the mapping is reasonably persistent (a month should be long enough), then we can define another resource to act as a mapping service. Such as,
which takes as input a userid (someone that a friend already knows and wants to monitor for changes) and returns the coordinate within the sparse array (the pixel within the 1000×1000 image) that corresponds to that user. FriendFeed can store that accumulated set of “interesting users” as another image file, using it like an “AND mask” filter to find the interesting changes on Flickr.
Note that this is all just a quick thought experiment based on the general idea. In order to build such a thing right, I’d have to know the internals of Flickr and what kinds of information FriendFeed is looking to receive, and there are many potential variations on the representations that might better suit those needs (for example, periods could be overlapped using gray-scale instead of B&W). The implementation has many other potential uses as well, since the sequence of images provide an active visualization of Flickr health.
I should also note that the above is not yet fully RESTful, at least how I use the term. All I have done is described the service interfaces, which is no more than any RPC. In order to make it RESTful, I would need to add hypertext to introduce and define the service, describe how to perform the mapping using forms and/or link templates, and provide code to combine the visualizations in useful ways. I could even go further and define these relationships as a standard, much like Atom has standardized a normal set of HTTP relationships with expected semantics, but I have bigger fish to fry right now.
The point is that you don’t need to change technologies (or even interaction styles) to solve a problem of information transfer efficiency. Sometimes you just need to rethink the problem. There are many systems for which a different architecture is far more efficient, just as XMPP is far more efficient than HTTP for something like group chat. Large-scale collaborative monitoring is not one of them. An XMPP solution is far more applicable to peer-to-peer monitoring, where there is no central service that is interested in the entire state of a big site like Flickr, but even then we have to keep in mind that the economics of the crowd will dictate scalability, not the protocol used for information transfer.
Tags: notifications , REST , scalability , webarch , XMPP
Mon 1 Sep 2008
Off the wagon
Posted by Roy T. Fielding under blogging Comments Off on Off the wagon
Hmm, over five months since my last (published) post. I don’t know how folks like Tim and Sam keep writing every day. I’ll have to ask when I see them at ApacheCon US in New Orleans .
I fell off the blogon while trying to prepare my two presentations for ApacheCon Europe and have yet to catch up with my email since then. Seriously, I spend way too much time reading and deleting email, so if you’ve sent me something and haven’t received a response then please understand that it isn’t because I don’t like you (unless, of course, you sent it to several of my email addresses at once, in which case it was probably blocked as spam).
Whenever I did find time to blog, I found myself wanting to update the software first, fiddle with the comment settings, or try out various blogspam avoidance tricks. My personal blog runs on WordPress , both because it’s cool cutting-edge open source software and because my ISP won’t let me run anything written in Java (let alone Day’s commercial products). It also has the nice side-effect of forcing me to pay attention to everyday web content management issues, instead of just the more abstract (implementation independent) issues of Web protocols. In other words, it keeps me in the loop in terms of what people are looking for in public-facing web content management. And, if I want to see what it looks like through our own software, I can just wander over to Planet Day .
One area in which open source blogging software is way ahead of the curve is support for collaborative antispam solutions. I’ve been much happier with my blog since I installed the TypePad Antispam plugin. The social filtering of blog spam is even more effective than it has been for Gmail, especially given the setting to automatically discard comments that look like spam on old posts. I wonder how long it would take Michael Marth to write an Apache Sling plugin for comment filtering using the TypePad service?
Tags: antispam , blogging , sling
Next Page »
- blogging (4)
- open source (3)
- software architecture (7)
- standards (2)
- system dynamics (1)
- web architecture (11)
Popular Tags:
antispam Apache architectural style AtomPub babylon5 blackboard blogging CMIS Connections courses economies of scale fatherhood hypertext ICSE information networks jabber James Burke Linda media types mime.types MIP notifications open development OpenSolaris open source precision REST ROA scalability semantic web sling software architecture specialization system dynamics systems engineering tuplespace twitter webarch WebDAV XMPP
The Unique Burial of a Child of Early Scythian Time at the Cemetery of Saryg-Bulun (Tuva)
<< Previous page
Pages: 379-406
In 1988, the Tuvan Archaeological Expedition (led by M. E. Kilunovskaya and V. A. Semenov) discovered a unique burial of the early Iron Age at Saryg-Bulun in Central Tuva. There are two burial mounds of the Aldy-Bel culture dated by 7th century BC. Within the barrows, which adjoined one another, forming a figure-of-eight, there were discovered 7 burials, from which a representative collection of artifacts was recovered. Burial 5 was the most unique, it was found in a coffin made of a larch trunk, with a tightly closed lid. Due to the preservative properties of larch and lack of air access, the coffin contained a well-preserved mummy of a child with an accompanying set of grave goods. The interred individual retained the skin on his face and had a leather headdress painted with red pigment and a coat, sewn from jerboa fur. The coat was belted with a leather belt with bronze ornaments and buckles. Besides that, a leather quiver with arrows with the shafts decorated with painted ornaments, fully preserved battle pick and a bow were buried in the coffin. Unexpectedly, the full-genomic analysis, showed that the individual was female. This fact opens a new aspect in the study of the social history of the Scythian society and perhaps brings us back to the myth of the Amazons, discussed by Herodotus. Of course, this discovery is unique in its preservation for the Scythian culture of Tuva and requires careful study and conservation.
Keywords: Tuva, Early Iron Age, early Scythian period, Aldy-Bel culture, barrow, burial in the coffin, mummy, full genome sequencing, aDNA
Information about authors: Marina Kilunovskaya (Saint Petersburg, Russian Federation). Candidate of Historical Sciences. Institute for the History of Material Culture of the Russian Academy of Sciences. Dvortsovaya Emb., 18, Saint Petersburg, 191186, Russian Federation E-mail: [email protected] Vladimir Semenov (Saint Petersburg, Russian Federation). Candidate of Historical Sciences. Institute for the History of Material Culture of the Russian Academy of Sciences. Dvortsovaya Emb., 18, Saint Petersburg, 191186, Russian Federation E-mail: [email protected] Varvara Busova (Moscow, Russian Federation). (Saint Petersburg, Russian Federation). Institute for the History of Material Culture of the Russian Academy of Sciences. Dvortsovaya Emb., 18, Saint Petersburg, 191186, Russian Federation E-mail: [email protected] Kharis Mustafin (Moscow, Russian Federation). Candidate of Technical Sciences. Moscow Institute of Physics and Technology. Institutsky Lane, 9, Dolgoprudny, 141701, Moscow Oblast, Russian Federation E-mail: [email protected] Irina Alborova (Moscow, Russian Federation). Candidate of Biological Sciences. Moscow Institute of Physics and Technology. Institutsky Lane, 9, Dolgoprudny, 141701, Moscow Oblast, Russian Federation E-mail: [email protected] Alina Matzvai (Moscow, Russian Federation). Moscow Institute of Physics and Technology. Institutsky Lane, 9, Dolgoprudny, 141701, Moscow Oblast, Russian Federation E-mail: [email protected]
Shopping Cart Items: 0 Cart Total: 0,00 € place your order
Price pdf version
student - 2,75 € individual - 3,00 € institutional - 7,00 €

Copyright В© 1999-2022. Stratum Publishing House
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser .
Enter the email address you signed up with and we'll email you a reset link.
- We're Hiring!
- Help Center

Land use changes in the environs of Moscow

Related Papers
Eurasian Geography and Economics
Grigory Ioffe
komal choudhary
This study illustrates the spatio-temporal dynamics of urban growth and land use changes in Samara city, Russia from 1975 to 2015. Landsat satellite imageries of five different time periods from 1975 to 2015 were acquired and quantify the changes with the help of ArcGIS 10.1 Software. By applying classification methods to the satellite images four main types of land use were extracted: water, built-up, forest and grassland. Then, the area coverage for all the land use types at different points in time were measured and coupled with population data. The results demonstrate that, over the entire study period, population was increased from 1146 thousand people to 1244 thousand from 1975 to 1990 but later on first reduce and then increase again, now 1173 thousand population. Builtup area is also change according to population. The present study revealed an increase in built-up by 37.01% from 1975 to 1995, than reduce -88.83% till 2005 and an increase by 39.16% from 2005 to 2015, along w...
Elena Milanova
Land use/Cover Change in Russia within the context of global challenges. The paper presents the results of a research project on Land Use/Cover Change (LUCC) in Russia in relations with global problems (climate change, environment and biodiversity degradation). The research was carried out at the Faculty of Geography, Moscow State University on the basis of the combination of remote sensing and in-field data of different spatial and temporal resolution. The original methodology of present-day landscape interpretation for land cover change study has been used. In Russia the major driver of land use/land cover change is agriculture. About twenty years ago the reforms of Russian agriculture were started. Agricultural lands in many regions were dramatically impacted by changed management practices, resulted in accelerated erosion and reduced biodiversity. Between the natural factors that shape agriculture in Russia, climate is the most important one. The study of long-term and short-ter...
Annals of The Association of American Geographers
Land use and land cover change is a complex process, driven by both natural and anthropogenic transformations (Fig. 1). In Russia, the major driver of land use / land cover change is agriculture. It has taken centuries of farming to create the existing spatial distribution of agricultural lands. Modernization of Russian agriculture started fifteen years ago. It has brought little change in land cover, except in the regions with marginal agriculture, where many fields were abandoned. However, in some regions, agricultural lands were dramatically impacted by changed management practices, resulting in accelerating erosion and reduced biodiversity. In other regions, federal support and private investments in the agricultural sector, especially those made by major oil and financial companies, has resulted in a certain land recovery. Between the natural factors that shape the agriculture in Russia, climate is the most important one. In the North European and most of the Asian part of the ...
Ekonomika poljoprivrede
Vasilii Erokhin
Journal of Rural Studies
judith pallot
In recent decades, Russia has experienced substantial transformations in agricultural land tenure. Post-Soviet reforms have shaped land distribution patterns but the impacts of these on agricultural use of land remain under-investigated. On a regional scale, there is still a knowledge gap in terms of knowing to what extent the variations in the compositions of agricultural land funds may be explained by changes in the acreage of other land categories. Using a case analysis of 82 of Russia’s territories from 2010 to 2018, the authors attempted to study the structural variations by picturing the compositions of regional land funds and mapping agricultural land distributions based on ranking “land activity”. Correlation analysis of centered log-ratio transformed compositional data revealed that in agriculture-oriented regions, the proportion of cropland was depressed by agriculture-to-urban and agriculture-to-industry land loss. In urbanized territories, the compositions of agricultura...
Open Geosciences
Alexey Naumov
Despite harsh climate, agriculture on the northern margins of Russia still remains the backbone of food security. Historically, in both regions studied in this article – the Republic of Karelia and the Republic of Sakha (Yakutia) – agricultural activities as dairy farming and even cropping were well adapted to local conditions including traditional activities such as horse breeding typical for Yakutia. Using three different sources of information – official statistics, expert interviews, and field observations – allowed us to draw a conclusion that there are both similarities and differences in agricultural development and land use of these two studied regions. The differences arise from agro-climate conditions, settlement history, specialization, and spatial pattern of economy. In both regions, farming is concentrated within the areas with most suitable natural conditions. Yet, even there, agricultural land use is shrinking, especially in Karelia. Both regions are prone to being af...
RELATED PAPERS
Giampaolo Francesconi
International Review of Environmental History
Rohan Howitt
Diego Aguilera
Matias Szabo
British Journal of Anaesthesia
Nanomaterials
Stefano Salvatori
Frontiers in Neurology
Nusrat Husain
Stefano Bottoni
Prokuratura i Prawo
youngyut predalumpaburt
Journal of Clinical Research in Pediatric Endocrinology
Firdevs Baş
Applied Surface Science
Valeryia Mikalayeva
2016 23rd International Conference on Pattern Recognition (ICPR)
Encyclopedia of Planetary Landforms
Erzsébet Illés-Almár
Giovanna Masala
Corpus Pragmatics
Marie Kopřivová
Journal of Virology
Participación política
Danko Jaccard
Ana Maria Brito
Reptiles & amphibians
Jay Bowerman
RELATED TOPICS
- We're Hiring!
- Help Center
- Find new research papers in:
- Health Sciences
- Earth Sciences
- Cognitive Science
- Mathematics
- Computer Science
- Academia ©2024
Current time by city
For example, New York
Current time by country
For example, Japan
Time difference
For example, London
For example, Dubai
Coordinates
For example, Hong Kong
For example, Delhi
For example, Sydney
Geographic coordinates of Elektrostal, Moscow Oblast, Russia
City coordinates
Coordinates of Elektrostal in decimal degrees
Coordinates of elektrostal in degrees and decimal minutes, utm coordinates of elektrostal, geographic coordinate systems.
WGS 84 coordinate reference system is the latest revision of the World Geodetic System, which is used in mapping and navigation, including GPS satellite navigation system (the Global Positioning System).
Geographic coordinates (latitude and longitude) define a position on the Earth’s surface. Coordinates are angular units. The canonical form of latitude and longitude representation uses degrees (°), minutes (′), and seconds (″). GPS systems widely use coordinates in degrees and decimal minutes, or in decimal degrees.
Latitude varies from −90° to 90°. The latitude of the Equator is 0°; the latitude of the South Pole is −90°; the latitude of the North Pole is 90°. Positive latitude values correspond to the geographic locations north of the Equator (abbrev. N). Negative latitude values correspond to the geographic locations south of the Equator (abbrev. S).
Longitude is counted from the prime meridian ( IERS Reference Meridian for WGS 84) and varies from −180° to 180°. Positive longitude values correspond to the geographic locations east of the prime meridian (abbrev. E). Negative longitude values correspond to the geographic locations west of the prime meridian (abbrev. W).
UTM or Universal Transverse Mercator coordinate system divides the Earth’s surface into 60 longitudinal zones. The coordinates of a location within each zone are defined as a planar coordinate pair related to the intersection of the equator and the zone’s central meridian, and measured in meters.
Elevation above sea level is a measure of a geographic location’s height. We are using the global digital elevation model GTOPO30 .
Elektrostal , Moscow Oblast, Russia
IMAGES
VIDEO
COMMENTS
CHAPTER 5. This chapter introduces and elaborates the Representational State Transfer (REST) architectural style for distributed hypermedia systems, describing the software engineering principles guiding REST and the interaction constraints chosen to retain those principles, while contrasting them to the constraints of other architectural styles.
UNIVERSITY OF CALIFORNIA, IRVINE Architectural Styles and the Design of Network-based Software Architectures DISSERTATION submitted in partial satisfaction of the requirements for the degree of
As mentioned, Fielding's dissertation is from 2000, but he began developing the ideas that later became REST as early as 1994. REST didn't come out of nowhere. Roy Fielding wasn't some random PhD student who sat in his ivory tower and came up with a bright idea. He was deeply involved in the web's early development and standardization.
Roy Fielding became involved in the Web Project while doing ... 2,000 startups with an "API" in their descriptions; about 50 specifi-cally highlight "REST APIs". This paper explores REST in a little detail, then proceeds to dis-cuss common misunderstandings about the work and perceived
Fielding's dissertation (titled "Architectural Styles and the Design of Network-based Software Architectures") is not about how to build APIs on top of HTTP but rather about HTTP itself. Fielding contributed to the HTTP/1.0 specification and co-authored the HTTP/1.1 specification, which was published in 1999.
A REST API should not be dependent on any single communication protocol, though its successful mapping to a given protocol may be dependent on the availability of metadata, choice of methods, etc. In general, any protocol element that uses a URI for identification must allow any URI scheme to be used for the sake of that identification.
Roy T. Fielding. Senior Principal Scientist, Adobe. Verified email at gbiv.com ... REST: architectural styles and the design of network-based software architectures ... Hypertext transfer protocol-HTTP/1.1, June 1999. R Fielding, J Gettys, J Mogul, H Frystyk, L Masinter, P Leach, ... Status: Standards Track 1 (11), 1829-1841, 1999. 292: 1999 ...
Around 2000, Roy T. Fielding formalized the idea of \how a well-designed Web ... from industry with a catalog of REST API design rules and asked them how ... The remaining paper is organized as follows: as a basis for the selection of rules, we discuss the architectural style REST as well as existing literature about ...
Roy T. Fielding reminisces about his PhD dissertation, which defined the Representational State Transfer architectural style. The first Web extra at http://yout
Roy Thomas Fielding (born 1965) is an American computer scientist, one of the principal authors of the HTTP specification and the originator of the Representational State Transfer (REST) architectural style. He is an authority on computer network architecture and co-founded the Apache HTTP Server project.. Fielding works as a Senior Principal Scientist at Adobe Systems in San Jose, California.
The Birth of REST: Roy Fielding's Dissertation. In 2000, Roy Fielding and his colleagues had one objective: Create a standard, so any server could talk to any other server in the world. ... Flickr's open REST API, for example, wasn't just used by lone bloggers and site builders—it was used as marketing for Flickr as a platform. The API ...
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity.
Roy T. Fielding talks with Charles Severance about his PhD dissertation, which defined the Representational State Transfer architectural style. From Computer...
Roy T. Fielding: Understanding the REST Style. C. Severance. Published in Computer 11 June 2015. Computer Science. TLDR. Roy T. Fielding reminisces about his PhD dissertation, which defined the Representational State Transfer architectural style, and talks with Charles Severance about his thesis. Expand.
In this Episode. Roy T. Fielding reminisces about his PhD dissertation, which defined the Representational State Transfer architectural style. From Computer's Issue 6, Vol 48 - June 2015. Roy T. Fielding: Understanding the REST Style.
REST is an acronym for REpresentational State Transfer and an architectural style for distributed hypermedia systems.Roy Fielding first presented it in 2000 in his famous dissertation.Since then it has become one of the most widely used approaches for building web-based APIs (Application Programming Interfaces).REST is not a protocol or a standard, it is an architectural style.
I was a Visiting Scholar at MIT/LCS during the summer of 1995, working with Tim Berners-Lee and the World Wide Web Consortium (W3C). You can see my old W3C Home . I was named by MIT Technology Review as one of the TR100: The top 100 young innovators for 1999. "The 100 young visionaries who our editors and a distinguished Panel of Judges feel ...
ICSE Most Influential Paper award. Posted by Roy T. Fielding under open source, software architecture, web architecture [5] Comments. ... A REST API should spend almost all of its descriptive effort in defining the media type(s) used for representing resources and driving application state, or in defining extended relation names and/or ...
Burial 5 was the most unique, it was found in a coffin made of a larch trunk, with a tightly closed lid. Due to the preservative properties of larch and lack of air access, the coffin contained a well-preserved mummy of a child with an accompanying set of grave goods. The interred individual retained the skin on his face and had a leather ...
Enter the email address you signed up with and we'll email you a reset link.
Zvenigorod's most famous sight is the Savvino-Storozhevsky Monastery, which was founded in 1398 by the monk Savva from the Troitse-Sergieva Lavra, at the invitation and with the support of Prince Yury Dmitrievich of Zvenigorod. Savva was later canonised as St Sabbas (Savva) of Storozhev. The monastery late flourished under the reign of Tsar ...
Geographic coordinate systems. WGS 84 coordinate reference system is the latest revision of the World Geodetic System, which is used in mapping and navigation, including GPS satellite navigation system (the Global Positioning System).