
Text-detection and -recognition from natural images
- Computer Science
Rights holder
Publication date, supervisor(s), qualification name, qualification level, this submission includes a signed certificate in addition to the thesis file(s).
- I have submitted a signed certificate
Administrator link
- https://repository.lboro.ac.uk/account/articles/11816514
Usage metrics
- Other information and computing sciences not elsewhere classified

- Show simple item record
- Show full item record
- Export item record
Files in This Item:
Page view(s) 50, download(s) 10.

Google Scholar TM
Items in DR-NTU are protected by copyright, with all rights reserved, unless otherwise indicated.
Help | Advanced Search
Computer Science > Computer Vision and Pattern Recognition
Title: continuous offline handwriting recognition using deep learning models.
Abstract: Handwritten text recognition is an open problem of great interest in the area of automatic document image analysis. The transcription of handwritten content present in digitized documents is significant in analyzing historical archives or digitizing information from handwritten documents, forms, and communications. In the last years, great advances have been made in this area due to applying deep learning techniques to its resolution. This Thesis addresses the offline continuous handwritten text recognition (HTR) problem, consisting of developing algorithms and models capable of transcribing the text present in an image without the need for the text to be segmented into characters. For this purpose, we have proposed a new recognition model based on integrating two types of deep learning architectures: convolutional neural networks (CNN) and sequence-to-sequence (seq2seq) models, respectively. The convolutional component of the model is oriented to identify relevant features present in characters, and the seq2seq component builds the transcription of the text by modeling the sequential nature of the text. For the design of this new model, an extensive analysis of the capabilities of different convolutional architectures in the simplified problem of isolated character recognition has been carried out in order to identify the most suitable ones to be integrated into the continuous model. Additionally, extensive experimentation of the proposed model for the continuous problem has been carried out to determine its robustness to changes in parameterization. The generalization capacity of the model has also been validated by evaluating it on three handwritten text databases using different languages: IAM in English, RIMES in French, and Osborne in Spanish, respectively. The new proposed model provides competitive results with those obtained with other well-established methodologies.
Submission history
Access paper:.
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
DBLP - CS Bibliography
Bibtex formatted citation.
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
GPT-4o: The Comprehensive Guide and Explanation

GPT-4o is OpenAI’s third major iteration of their popular large multimodal model , GPT-4, which expands on the capabilities of GPT-4 with Vision . The newly released model is able to talk, see, and interact with the user in an integrated and seamless way, more so than previous versions when using the ChatGPT interface.
In the GPT-4o announcement , OpenAI focused the model’s ability for "much more natural human-computer interaction". In this article, we will discuss what GPT-4o is, how it differs from previous models, evaluate its performance, and use cases for GPT-4o.
What is GPT-4o?
OpenAI’s GPT-4o, the “o” stands for omni (meaning ‘all’ or ‘universally’), was released during a live-streamed announcement and demo on May 13, 2024. It is a multimodal model with text, visual and audio input and output capabilities, building on the previous iteration of OpenAI’s GPT-4 with Vision model , GPT-4 Turbo. The power and speed of GPT-4o comes from being a single model handling multiple modalities. Previous GPT-4 versions used multiple single purpose models (voice to text, text to voice, text to image) and created a fragmented experience of switching between models for different tasks.
Compared to GPT-4T, OpenAI claims it is twice as fast, 50% cheaper across both input tokens ($5 per million) and output tokens ($15 per million), and has five times the rate limit (up to 10 million tokens per minute). GPT-4o has a 128K context window and has a knowledge cut-off date of October 2023. Some of the new abilities are currently available online through ChatGPT, through the ChatGPT app on desktop and mobile devices, through the OpenAI API ( see API release notes ), and through Microsoft Azure .
What’s New in GPT-4o?
While the release demo only showed GPT-4o’s visual and audio capabilities, the release blog contains examples that extend far beyond the previous capabilities of GPT-4 releases. Like its predecessors, it has text and vision capabilities, but GPT-4o also has native understanding and generation capabilities across all its supported modalities, including video.
As Sam Altman points out in his personal blog , the most exciting advancement is the speed of the model, especially when the model is communicating with voice. This is the first time there is nearly zero delay in response and you can engage with GPT-4o similarly to how you interact in daily conversations with people.
Less than a year after releasing GPT-4 with Vision (see our analysis of GPT-4 from September 2023), OpenAI has made meaningful advances in performance and speed which you don’t want to miss.
Let’s get started!
Text Evaluation of GPT-4o
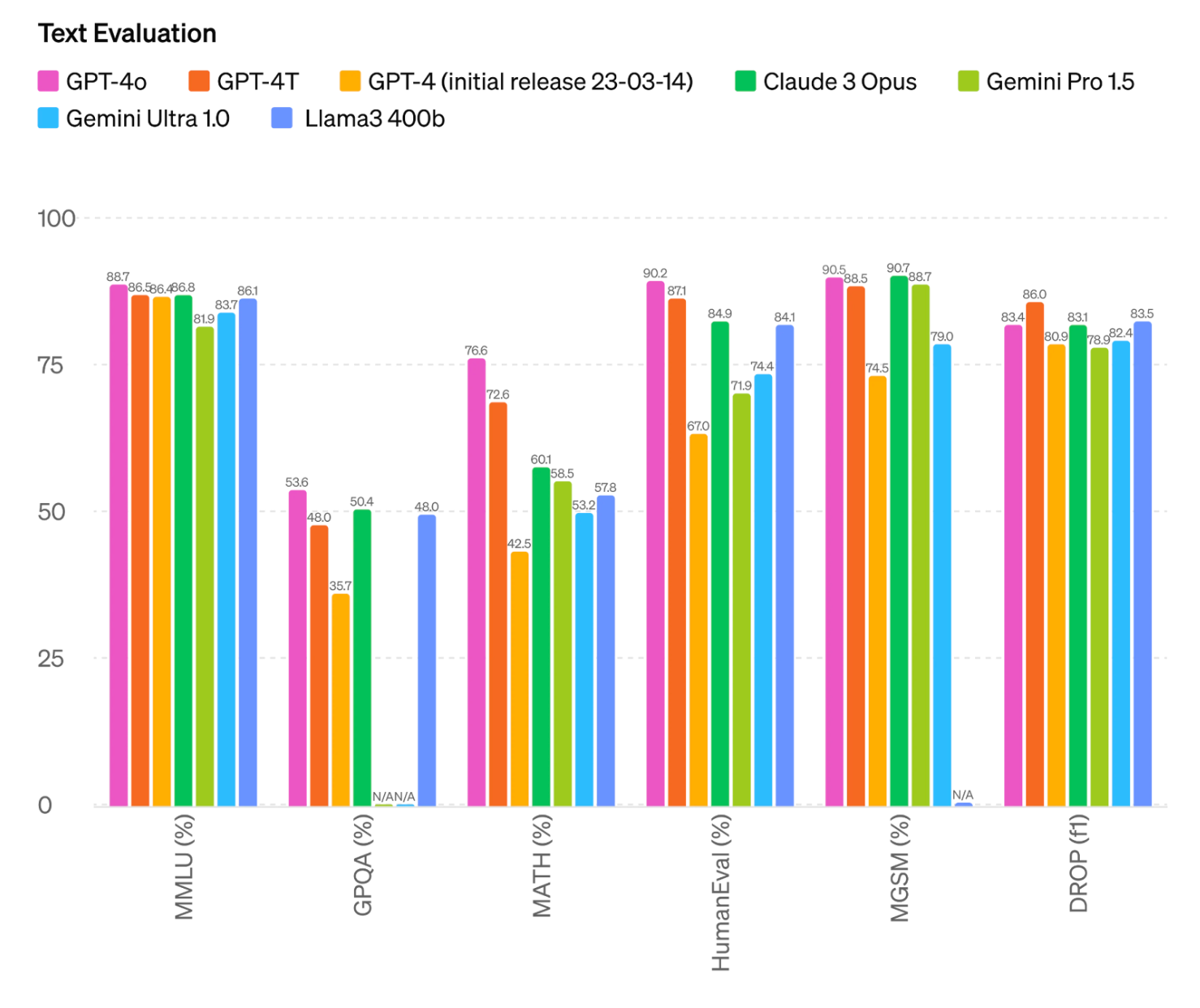
For text, GPT-4o features slightly improved or similar scores compared to other LMMs like previous GPT-4 iterations, Anthropic's Claude 3 Opus, Google's Gemini and Meta's Llama3, according to self-released benchmark results by OpenAI.
Note that in the text evaluation benchmark results provided, OpenAI compares the 400b variant of Meta’s Llama3. At the time of publication of the results, Meta has not finished training its 400b variant model.
Video Capabilities of GPT-4o
Important note from the API release notes regarding use with video: “GPT-4o in the API supports understanding video (without audio) via vision capabilities. Specifically, videos need to be converted to frames (2-4 frames per second, either sampled uniformly or via a keyframe selection algorithm) to input into the model.” Use the OpenAI cookbook for vision to better understand how to use video as an input and the limitations of the release.
GPT-4o is demonstrated having both the ability to view and understand video and audio from an uploaded video file, as well as the ability to generate short videos.
Within the initial demo, there were many occurrences of GPT-4o being asked to comment on or respond to visual elements. Similar to our initial observations of Gemini , the demo didn’t make it clear if the model was receiving video or triggering an image capture whenever it needed to “see” real-time information. There was a moment in the initial demo where GPT-4o may have not triggered an image capture and therefore saw the previously captured image.
In this demo video on YouTube , GPT-4o “notices” a person coming up behind Greg Brockman to make bunny ears. On the visible phone screen, a “blink” animation occurs in addition to a sound effect. This means GPT-4o might use a similar approach to video as Gemini, where audio is processed alongside extracted image frames of a video.

The only demonstrated example of video generation is a 3D model video reconstruction, though it is speculated to possibly have the ability to generate more complex videos.

An exchange between GPT-4o where a user requests and receives a 3D video reconstruction of a spinning logo based on several reference images
Audio Capabilities of GPT-4o
Similar to video and images, GPT-4o also possesses the ability to ingest and generate audio files.
GPT-4o shows an impressive level of granular control over the generated voice, being able to change speed of communication, alter tones when requested, and even sing on demand. Not only could GPT-4o control its own output, it has the ability to understand the sound of input audio as additional context to any request. Demos show GPT-4o giving tone feedback to someone attempting to speak Chinese as well as feedback on the speed of someone’s breath during a breathing exercise.
According to self-released benchmarks, GPT-4o outperforms OpenAI’s own Whisper-v3, the previous state-of-the-art in automatic speech recognition (ASR) and outperforms audio translation by other models from Meta and Google.
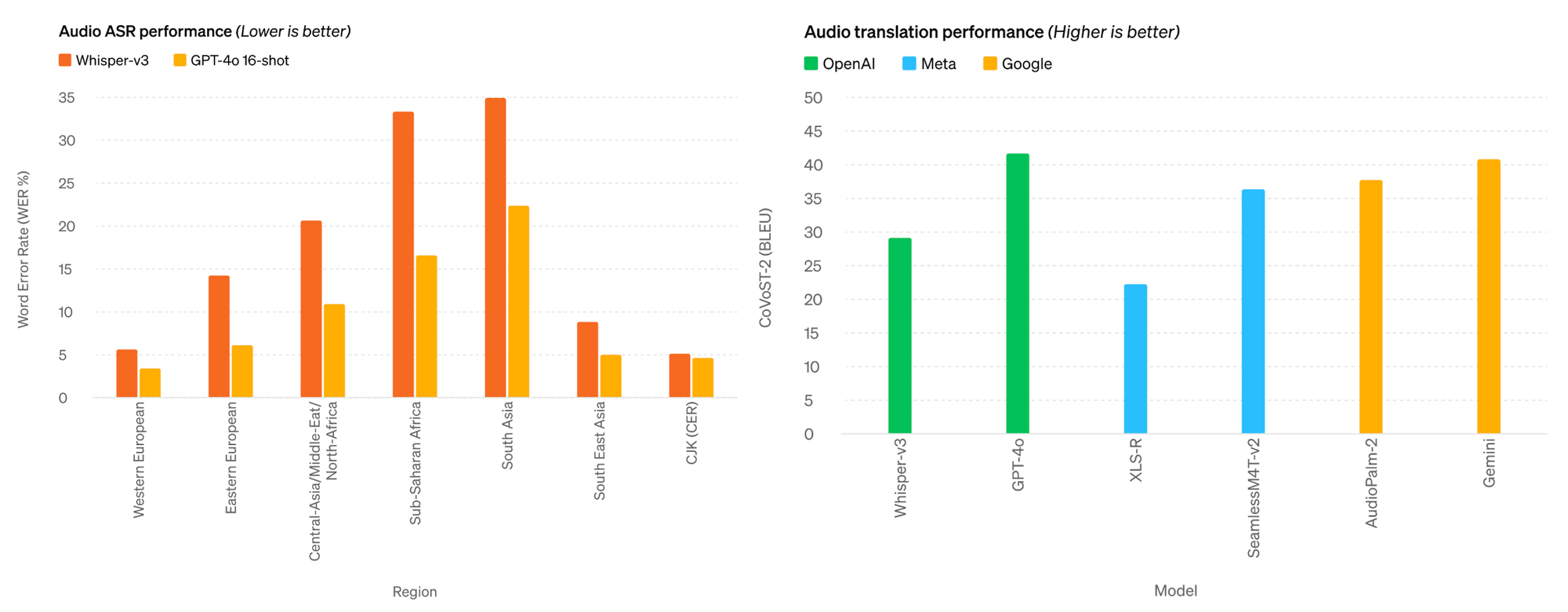
Image Generation with GPT-4o
GPT-4o has powerful image generation abilities, with demonstrations of one-shot reference-based image generation and accurate text depictions.
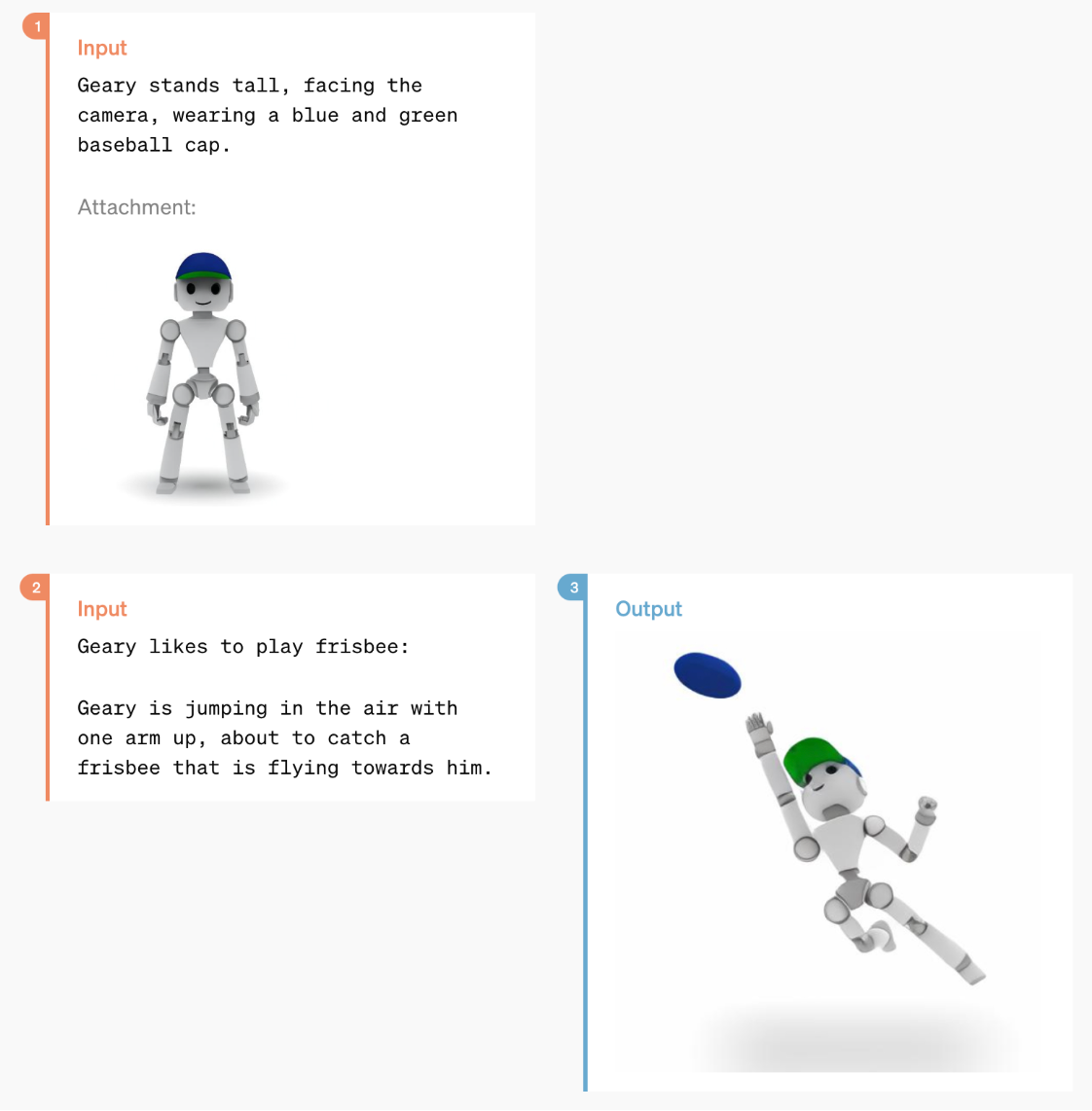
User/GPT-4o exchanges generating images (Image Credit: OpenAI)
The images below are especially impressive considering the request to maintain specific words and transform them into alternative visual designs. This skill is along the lines of GPT-4o’s ability to create custom fonts.

Visual Understanding of GPT-4o
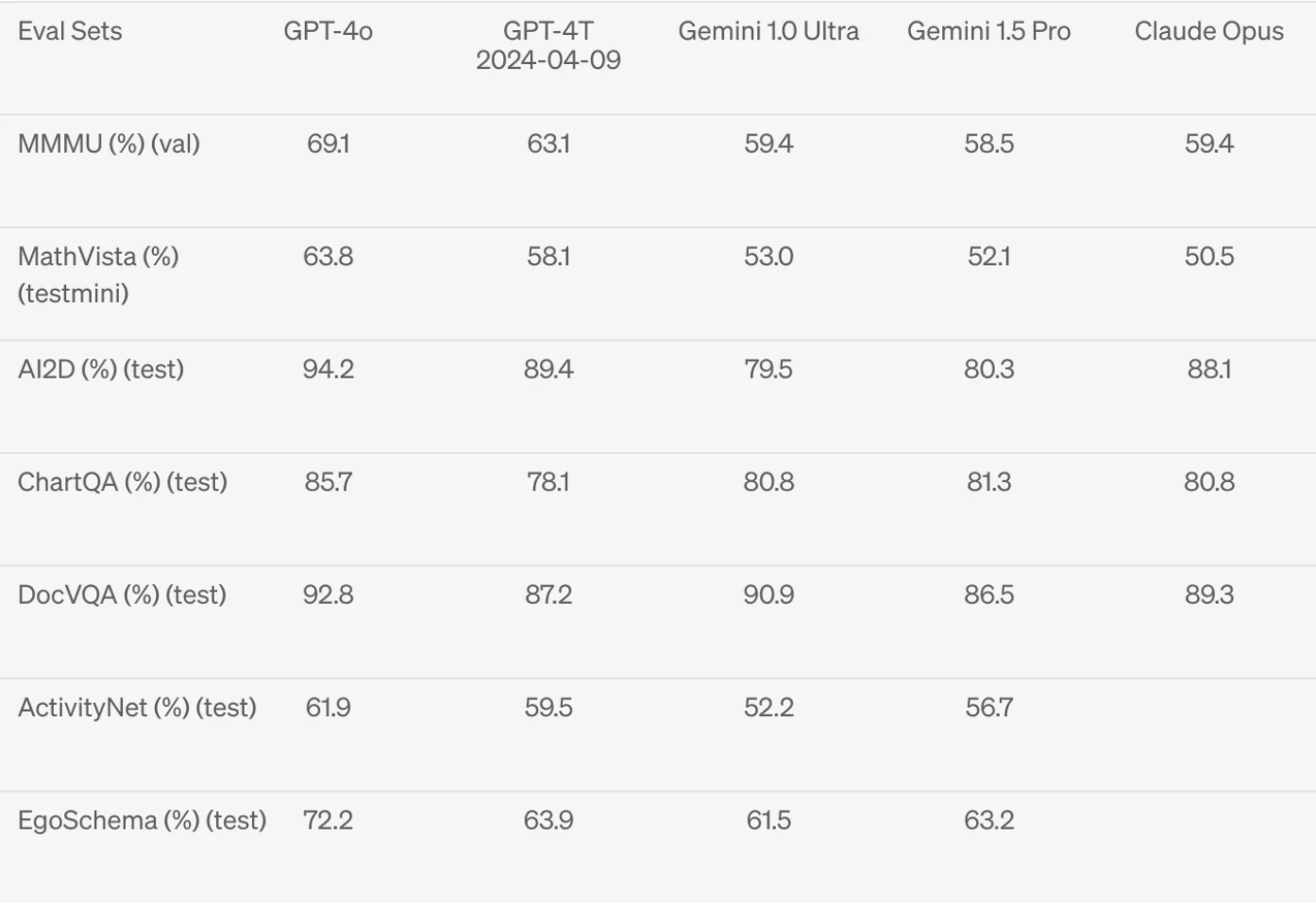
Although state-of-the-art capability that existed in previous iterations, visual understanding is improved, achieving state of the art across several visual understanding benchmarks against GPT-4T, Gemini, and Claude. Roboflow maintains a less formal set of visual understanding evaluations, see results of real world vision use cases for open source large multimodal models .
Although the OCR capability of GPT-4o was not published by OpenAI, we will evaluate it later in this article.
Evaluating GPT-4o for Vision Use Cases
Next, we use both the OpenAI API and the ChatGPT UI to evaluate different aspects of GPT-4o, including optical character recognition (OCR), document OCR, document understanding, visual question answering (VQA) and object detection .

Optical Character Recognition (OCR) with GPT-4o
OCR is a common computer vision task to return the visible text from an image in text format. Here, we prompt GPT-4o to “Read the serial number.” and “Read the text from the picture”, both of which it answers correctly.

Next, we evaluated GPT-4o on the same dataset used to test other OCR models on real-world datasets.
Here we find a 94.12% average accuracy (+10.8% more than GPT-4V), a median accuracy of 60.76% (+4.78% more than GPT-4V) and an average inference time of 1.45 seconds.
The 58.47% speed increase over GPT-4V makes GPT-4o the leader in the category of speed efficiency (a metric of accuracy given time, calculated by accuracy divided by elapsed time).

Document Understanding with GPT4-o
Next, we evaluate GPT-4o’s ability to extract key information from an image with dense text. Prompting GPT-4o with “How much tax did I pay?” referring to a receipt, and “What is the price of Pastrami Pizza” in reference to a pizza menu, GPT-4o answers both of these questions correctly.
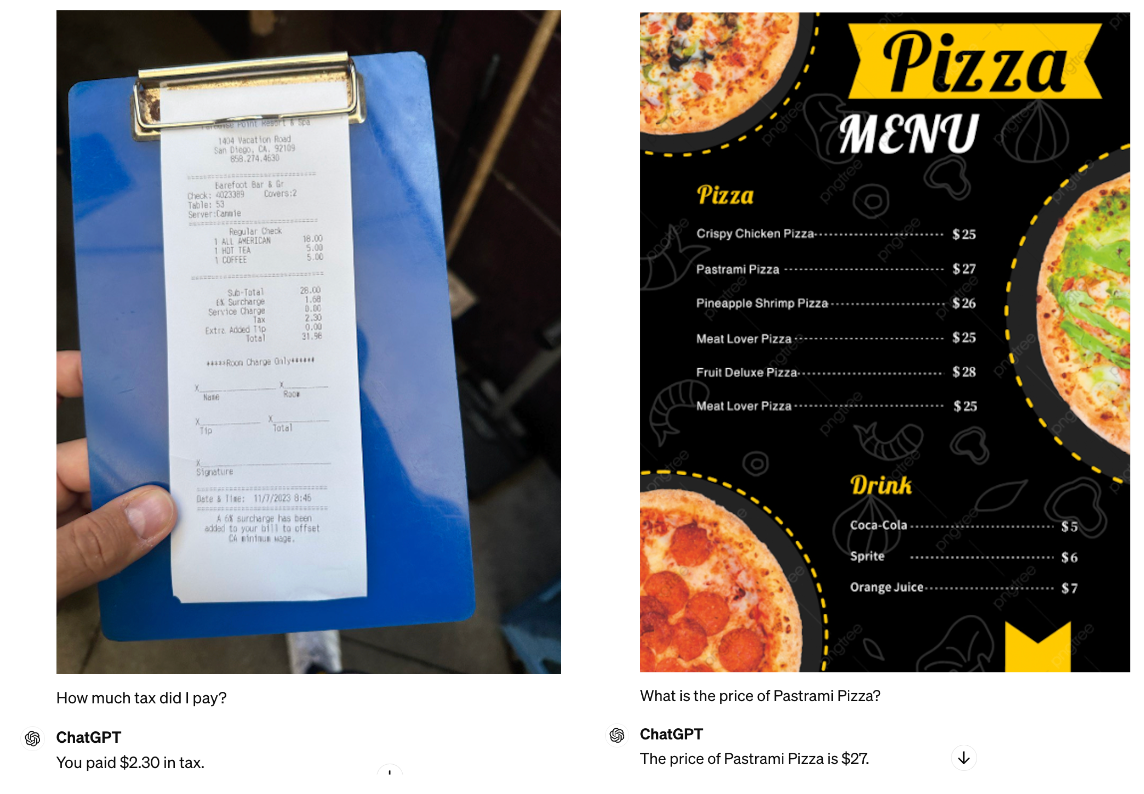
This is an improvement from GPT-4 with Vision, where it failed the tax extraction from the receipt.
Visual Question Answering with GPT-4o
Next is a series of visual question and answer prompts. First, we ask how many coins GPT-4o counts in an image with four coins.
GPT-4o the answer of five coins. However, when retried, it did answer correctly. This change in response is a reason a site call GPT Checkup exists – closed-source LMM performance changes overtime and it’s important to monitor how it performs so you can confidently use an LMM in your application.

This suggests that GPT-4o suffers from the same inconsistent ability to count as we saw in GPT-4 with Vision.
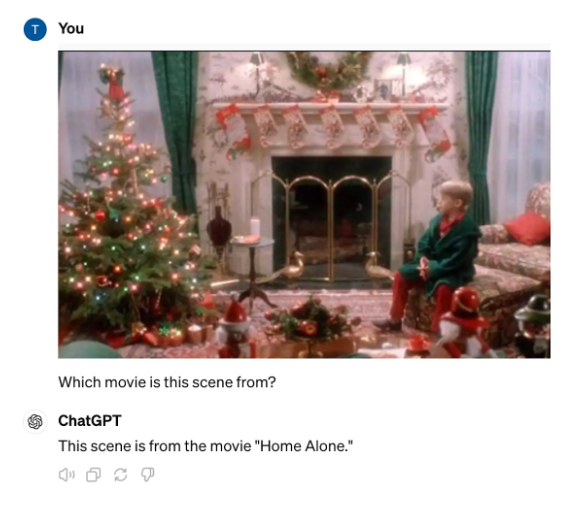
Further, GPT-4o correctly identifies an image from a scene of Home Alone.
Object Detection with GPT-4o
Finally, we test object detection, which has proven to be a difficult task for multimodal models. Where Gemini, GPT-4 with Vision, and Claude 3 Opus failed, GPT-4o also fails to generate an accurate bounding box.

GPT-4o Use Cases
As OpenAI continues to expand the capabilities of GPT-4, and eventual release of GPT-5, use cases will expand exponentially. The release of GPT-4 made image classification and tagging extremely easy, although OpenAI’s open source CLIP model performs similarly for much cheaper. Adding vision capabilities made it possible to combine GPT-4 with other models in computer vision pipelines which creates the opportunity to augment open source models with GPT-4 for a more fully featured custom application using vision.
A few key elements of GPT-4o opens up another set of use cases that were previously not possible and none of these use cases have anything to do with better model performance on benchmarks. Sam Altman’s personal blog states they have a clear intention to “Create AI and then other people will use it to create all sorts of amazing things that we all benefit from“. If OpenAI’s goal is to keep driving cost down and improve performance, where does that take things?
Let’s consider a few new use cases.
Real-time Computer Vision Use Cases
The new speed improvements matched with visual and audio finally open up real-time use cases for GPT-4, which is especially exciting for computer vision use cases. Using a real-time view of the world around you and being able to speak to a GPT-4o model means you can quickly gather intelligence and make decisions. This is useful for everything from navigation to translation to guided instructions to understanding complex visual data.
Interacting with GPT-4o at the speed you’d interact with an extremely capable human means less time typing text to us AI and more time interacting with the world around you as AI augments your needs.
One-device Multimodal Use Cases
Enabling GPT-4o to run on-device for desktop and mobile (and if the trend continues, wearables like Apple VisionPro ) lets you use one interface to troubleshoot many tasks. Rather than typing in text to prompt your way into an answer, you can show your desktop screen. Instead of copying and pasting content into the ChatGPT window, you pass the visual information while simultaneously asking questions. This decreases switching between various screens and models and prompting requirements to create an integrated experience.
GPT4-o’s single multimodal model removes friction, increases speed, and streamlines connecting your device inputs to decrease the difficulty of interacting with the model.
General Enterprise Applications
With additional modalities integrating into one model and improved performance, GPT-4o is suitable for certain aspects of an enterprise application pipeline that do not require fine-tuning on custom data. Although considerably more expensive than running open source models, faster performance brings GPT-4o closer to being useful when building custom vision applications.
You can use GPT-4o where open source models or fine-tuned models aren’t yet available, and then use your custom models for other steps in your application to augment GPT-4o’s knowledge or decrease costs. This means you can quickly start prototyping complex workflows and not be blocked by model capabilities for many use cases.
GPT-4o’s newest improvements are twice as fast, 50% cheaper, 5x rate limit, 128K context window, and a single multimodal model are exciting advancements for people building AI applications. More and more use cases are suitable to be solved with AI and the multiple inputs allow for a seamless interface.
Faster performance and image/video inputs means GPT-4o can be used in a computer vision workflow alongside custom fine-tuned models and pre-trained open-source models to create enterprise applications.
Cite this Post
Use the following entry to cite this post in your research:
Leo Ueno , Trevor Lynn . (May 14, 2024). GPT-4o: The Comprehensive Guide and Explanation. Roboflow Blog: https://blog.roboflow.com/gpt-4o-vision-use-cases/
Discuss this Post
If you have any questions about this blog post, start a discussion on the Roboflow Forum .
ML Growth Associate @ Roboflow | Sharing the magic of computer vision | leoueno.com
Table of Contents
How to fine-tune paligemma for object detection tasks, finetuning moondream2 for computer vision tasks, paligemma: an open multimodal model by google, ultimate guide to using clip with intel gaudi2, launch: yolo-world support in roboflow, best ocr models for text recognition in images.
- International Journal of Engineering Research & Technology (IJERT)
- Mission & Scope
- Editorial Board
- Peer-Review Policy
- Publication Ethics Policy
- Journal Policies
- Join as Reviewer
- Conference Partners
- Call for Papers
- Journal Statistics – 2023-2024
- Submit Manuscript
- Journal Charges (APC)
- Register as Volunteer
- Upcoming Conferences
- CONFERENCE PROCEEDINGS
- Thesis Archive
- Thesis Publication FAQs
- Thesis Publication Charges
- Author Login
- Reviewer Login
Volume 13, Issue 05 (May 2024)
Application of machine learning for automatic number plate recognition using optical character recognition engine.
- Article Download / Views: 9
- Authors : Osakwe Anthony Abuchi, Dr. Arul Lenna Rose .P.J, Dr. Aarthi. E
- Paper ID : IJERTV13IS050144
- Volume & Issue : Volume 13, Issue 05 (May 2024)
- Published (First Online): 17-05-2024
- ISSN (Online) : 2278-0181
- Publisher Name : IJERT

Published by : http://www.ijert.org
International Journal of Engineering Research & Technology (IJERT)
ISSN: 2278-0181
Vol. 13 Issue 5, May 2024
Abstract—In Nigeria, traffic control management, vehicle real- time tracking and vehicle identification have become imperative to law enforcement to enable them to digitalize or make use of computer vision to easily carry out tasks like identifying traffic offenders, tracking stolen vehicle plates in real time using traffic cams and ultimately identifying vehicle ownership using plate number in seconds. Hence, there is a need to introduce an innovative system, leveraging machine learning and optical character recognition using OpenCV and TensorFlow to produce an effective automatic number plate recognition (ANPR) software to combat such issues. This research paper seeks to use a novel methodology by using TensorFlow for model training and OpenCV for processing number plate photos to achieve identification. The recognized plate numbers will then be stored in a database.
Keywords—Automatic Number Plate Recognition (ANPR), Optical Character Recognition (OCR), Convolutional Neural Networks (CNNs).
INTRODUCTION
Smart transportation and effective enforcement of traffic rules on motorists by utilizing traffic cams is based on the Automatic Number plate Recognition System. Recognition and identification of number plates are achieved without direct human involvement in any way by ANPR. Proficiency in this discipline is imperative for efficiently and expeditiously discerning vehicle registration plates. It is used in many scenarios such as managing parking lots, enforcing traffic laws, and collecting road tolls. Researchers have concluded that ANPR algorithms are divided into 4 generic steps:
(1) Vehicle plate image capture (2) Vehicle plate number detection (3) Segmentation of characters and (4) Recognition of characters.
The first step vehicle plate image capture particularly refers to the technique of collecting photographs of license plates from vehicles, secondly, vehicle plate number detection, sometimes referred to as license plate recognition (LPR), is the process of mechanically extracting the license plate numbers from collected photographs, thirdly, character segmentation is an essential process in optical character recognition (OCR) systems. Its purpose is to recognize and extract individual characters from the identified Nigerian car plate and lastly, character recognition is the ultimate stage in the process of Automatic Number Plate Recognition (ANPR). During this stage, the system identifies and converts the individual characters on the license plate into text that can be read by a human.
Based on a dataset of over 1000 vehicles with number plates from Kaggle an open source dataset library from Google and manually obtained vehicle number plates of cars from different states in Nigeria of over 500 in number, this paper aims at using 1,100 as training dataset and 400 as testing data to utilize computer vision technology to automatically identify Nigerian made number plates effectively with high output rate.
LITERATURE SURVEY
We have thoroughly assessed other research articles on the subject and used the most effective strategies in our study. We have synthesized a concise comprehension derived from several referenced works in this research.
To locate the license plate position of a Chinese car A method for calculating vertical as well as horizontal disparities to produce an exact rectangle with a vehicle number was proposed by Hui Wu and Bing Li
0.8 seconds.
A clever edge detector operator was used in
to identify the transition points. A driver's license plate contains black characters on a white background, according to H.Erdinc Kocer et al. The noise is removed by the Canny edge detector by applying a filter that is based on the first derivative of Gaussian smoothing. The gradient of the picture is then taken into account when estimating the edge strength in the next phase. To get this assignment, the astute edge detector operator used a 3 X 3 matrix. The zone of transition points is computed using this data. The transition spots between the colours black and white are found using the edge map. The more intricate technical details of this process are not given. A CCD camera was used to take the pictures of the cars.
Improved segmentation techniques have been presented by Ankush Roy et al.
for the purpose of distinguishing number plates of different countries. To remove noise, binarize the picture, label pixels based on colour values, segment the 15 × 15 plate, and partition the image, four steps are involved: median filtering, adaptive thresholding, component labelling, region growth, and segmentation and normalization. For image binarization in the adaptive thresholding process, the authors used Otsu's method. The system's overall success rate is given; however, this research makes no mention of the number plate detection rate's success rate.
An alternative SCW-based technique for locating Korean license plates is given in
to facilitate faster recognition of regions of interest (ROIs). The two-step procedure shifts the top left corner of the picture by two concentric windows. The segmentation rule, which specifies that the centre pixel of the frames is judged to be a component of an ROI if the ratio of the mean or median in the two windows over a threshold as set by the, was then used to construct statistical indicators for both windows. The two windows will stop sliding when the whole image has been scanned. The threshold value may be found
via a combination of trial and error approaches. A connected component assessment is also used in order to get a 96% overall success rate. In this experiment, a Pentium IV operating at 3.0 GHz with 512 MB of RAM completed license plate segmentation in 111m.
The writers of reference
used a weighted statistics technique. Before doing any analysis, they first turned a 24-bit colour picture into a grayscale form. For processing, the picture was represented as a 2D matrix with N rows and M columns. They carried out a weighting method and improved the picture matrix by adding weights. The standard ratio for license plate dimensions is 3.14:1, according to Zhigang Zhang et al. Nevertheless, the technical details of this approach are not covered in this article. An analogous method is suggested in reference
EXISTING SYSTEM
recognition of characters and the use of different algorithms for registration plate identification have a favourable impact on the analysis of registration plate images. Thus, they serve as the core component of any ANPR system. The ANPR system consists of a camera, image processing software, a computer system, and a frame grabber for analysis and recognition. The significance of Number Plate Recognition has significantly increased in recent years. Extensive studies have been conducted to identify different types of vehicles, such as cars and trucks. The Support Vector Machine [9] is used for car model identification. They presented the quantitative results using over 50 data set images. There is a sufficient array of programs and software accessible on the market to identify license plates. These systems effectively fulfil their objective with few constraints. Some of these applications need an extensive period of identification and also demand images of excellent quality.
Certain important drawbacks of the present system are discussed below. These also cause some hinges to our goal and we aim at deleting most of them in our future modifications.
Number plates from two or more states might have the same number pattern but different designs, including those automobiles belonging to dignitaries and government officials with distinct makeup.
Automobile lane change at the point of ANPR camera scanning the plates.
A piece of dirt or dust particles covering the plate or some part of the plate.
Blurry visuals, especially due to the high speed of vehicles.
Inadequate lighting and low contrast owing to prolonged exposure and reflection of shadows.
Low image resolution, generally because the plate is too distant but occasionally arising from the adoption of black and white quality cameras.
PROPOSED SYSTEM
Nigeria, a nation of approximately 218.5 million people in an area of 923,768 km2 (356,669 sq mi) according to Wikipedia, has unique demands for the ANPR system than other nations. The primary applications of ANPR are in parking control, traffic surveillance, and community law enforcement security. In Nigeria, there is one fatality for every four minutes, most of which are caused by speeding and bad roads. The average speed of the cars can be tracked by ANPR if implemented, which may also be used to detect cars that go above the speed limit stipulated by the law. This contributes to the preservation of law and order, which may reduce the amount of people killed on the roads.
Fig. ANPR System.
Both the hardware and the software parameters were taken into consideration when the ANPR System was implemented. Together with several Python libraries, TensorFlow and OpenCV are essential components of a successful Automatic Number Plate Recognition (ANPR) system. Licensing plate pictures for analysis requires image preparation using OpenCV, which includes activities like scaling, boosting contrast, and filtering. Next, by using TensorFlow, one may train a Convolutional Neural Network (CNN) model to precisely identify license plates in pictures.
Fig. Output Images
Convolutional Neural Networks
The Convolutional Neural Network (CNN) model is essential in the Automatic Number Plate Recognition (ANPR) system for precise detection and identification of characters on license plates. A Convolutional Neural Network (CNN) is a specialized deep learning model that is particularly effective in handling visual input. It is primarily built for tasks such as object identification and picture recognition. The Convolutional Neural Network (CNN) in the Automatic Number Plate Recognition (ANPR) system is trained using extensive datasets of license plate photos that have been annotated. Through this training, the CNN learns to recognize and differentiate characters from background noise and other components inside the image by identifying certain patterns and characteristics. After being trained, the Convolutional Neural Network (CNN) analyzes incoming license plate photos by using convolutional filters to extract important characteristics.
but nevertheless maintained an efficacy level of over 80%. The results emphasize the capability of ANPR systems using OpenCV and TensorFlow to successfully detect license plates in various geographical settings. These findings provide useful information for improving and implementing these systems in practical scenarios.
Fig. Detection Rate of Plate Numbers.
Fig. CNN Architecture.
VI. CONCLUSION AND FUTURE WORK
To summarize, this research demonstrates that ANPR systems including OpenCV and TensorFlow are very successful in accurately detecting license plates in different Nigerian states. The shown performance, with an average detection rate varying from 80% to 88%, highlights the potential of these technologies in improving vehicle recognition and tracking capabilities. In the future, it is recommended to prioritize enhancing the system's capacity to identify certain types of license plates, such as those used by government, military forces, and diplomatic vehicles. These
The dataset consists of more than 1000 automobiles with number plates sourced from Kaggle, an open-source dataset library by Google. Additionally, it includes around 500 vehicle number plates from in several states in Nigeria sourced from Google.
Among the several methods considered in this research, Automatic Number Plate Recognition (ANPR) using OpenCV and TensorFlow proved to be the most effective, taking into account the inherent constraints of an ANPR system. By using these technologies, we gathered a complete dataset consisting of photographs from different regions in Nigeria. The dataset contains a total of 400 images, largely obtained from Google. The Automatic Number Plate Recognition (ANPR) system demonstrated a favourable performance, with an average detection rate ranging from 80% to 88% across several states. States like Lagos, Rivers, and Imo had a very high detection rate of 88%, which suggests a strong ability to recognize license plates. In contrast, states like Kogi and Yobe had somewhat lower rates
plates may have distinct characteristics that are not currently well accounted for in the existing study. This may include integrating supplementary image processing methodologies and training the model on a mre varied dataset that encompasses examples of these specific plates. Moreover, investigating sophisticated machine learning methods and adding domain-specific information might further boost the system's accuracy and resilience in detecting specialty license plates, hence broadening its usefulness in real-world settings.
Hui Wu and Bing Li, "License Plate Recognition System," in International Conference on Multimedia Technology (ICMT), 2011,
pp. 5425-5427.
H. Erdinc Kocer and K. Kursat Cevik, "Artificial neural netwokrs based vehicle license plate recognition," Procedia Computer Science, vol. 3,
pp. 1033-1037, 2011.
A Roy and D.P Ghoshal, "Number Plate Recognition for use in different countries using an improved segmenation," in 2nd National Conference on Emerging Trends and Applications in Computer Science(NCETACS), 2011, pp. 1-5.
Kaushik Deb, Ibrahim Kahn, Anik Saha, and Kang-Hyun Jo, "An Efficeint Method of Vehicle License Plate Recognition Based on Sliding Concentric Windows and Artificial Neural Network," Procedia Technology, vol. 4, pp. 812-819, 2012.
Christos Nikolaos E. Anagnostopoulos, Ioannis E. Anagnostopoulos, Vassili Loumos, and Eleftherios Kayafas, "A License Plate- Recognition Algorithm for Intelligent Transportation System Applications," pp. 377- 392, 2006.
Fikriye Öztürk and Figen Özen, "A New License Plate Recognition System Based on Probabilistic Neural Networks," Procedia Technology, vol. 1, pp. 124-128, 2012.
Ch.Jaya Lakshmi, Dr.A.Jhansi Rani, Dr.K.Sri Ramakrishna, and M. KantiKiran, "A Novel Approach for Indian License Recognition System," International Journal of Advanced Engineering Sciences and Technologies, vol. 6, no. 1, pp. 10-14, 2011.
R Zunino and S Rovetta, "Vector quantization for license-plate location and image coding," IEEE Transactions on Industrial Electornics, vol. 47, no. 1, pp. 159-167, 2000.
Ying Wen et al., "An Algorithm for License Plate recognition Applied to Intelligent Transportation System," IEEE Transactions of Intelligent Transportation Systems, pp. 1-16, 2011.
Yang Yang, Xuhui Gao, and Guowei Yang, "Study the Method of Vehicle License Locating Based on Color Segmentation," Procedia Engineering , vol. 15, pp. 1324- 1329, 2011.
Yifan Zhu, Han Huang, Zhenyu Xu, Yiyu He, and Shiqiu Liu, "Chinese-style Plate Recognition Based on Artificaial Neural Network and Statistics," Procedia Engineering, vol. 15, pp. 3556-3561, 2011.
Lihong Zheng, Xiangjian He, Bijan Samali, and Laurence T. Yang, "An algorithm for accuracy enhancement of license recognition," Journal of Computer and System Sciences, , 2012.
Anton Satria Prabuwono and Ariff Idris, "A Study of Car Park Control System Using Optical Character Recognition ," in International Conference on Computer and Electrical Engineering, 2008, pp. 866- 870.
Francisco Moraes Oliveira-Neto, Lee D. Han, and Myong K Jeong, "Online license plate matching procedures using license-plate recognition machine and new weighted edit distance," Transportation Research Part C: Emerging Technologies, vol. 21, no. 1, pp. 306- 320,
April 2012.
Scene text detection and recognition with advances in deep learning: a survey
- Original Paper
- Published: 27 March 2019
- Volume 22 , pages 143–162, ( 2019 )
Cite this article

- Xiyan Liu 1 , 2 ,
- Gaofeng Meng ORCID: orcid.org/0000-0002-7103-6321 1 &
- Chunhong Pan 1
3783 Accesses
72 Citations
6 Altmetric
Explore all metrics
Scene text detection and recognition has become a very active research topic in recent several years. It can find many applications in reality ranging from navigation for vision-impaired people to semantic natural scene understanding. In this survey, we are intended to give a thorough and in-depth reviews on the recent advances on this topic, mainly focusing on the methods that appeared in the past 5 years for text detection and recognition in images and videos, including the recent state-of-the-art techniques on the following three related topics: (1) scene text detection, (2) scene text recognition and (3) end-to-end text recognition system. Compared with the previous survey, this survey pays more attention to the application of deep learning techniques on scene text detection and recognition. We also give a brief introduction of other related works such as script identification, text/non-text classification and text-to-image retrieval. This survey also reviews and summarizes some benchmark datasets that are widely used in the literature. Based on these datasets, performances of state-of-the-art approaches are shown and discussed. Finally, we conclude this survey by pointing out several potential directions on scene text detection and recognition that need to be well explored in the future.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price excludes VAT (USA) Tax calculation will be finalised during checkout.
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions

Similar content being viewed by others

Scene Text Recognition: An Overview

Text detection, recognition, and script identification in natural scene images: a Review

Scene Text Detection and Recognition: The Deep Learning Era
Neumann, L., Matas, J.: A method for text localization and recognition in real-world images. In: Asian Conference on Computer Vision, pp. 770–783. Springer (2010)
Epshtein, B., Ofek, E., Wexler, Y.: Detecting text in natural scenes with stroke width transform. In: 2010 IEEE Conference on CVPR, pp. 2963–2970. IEEE (2010)
Yin, X.C., Yin, X., Huang, K., Hao, H.W.: Robust text detection in natural scene images. IEEE Trans. PAMI 36 (5), 970–983 (2014)
Article Google Scholar
Neumann, L., Matas, J.: Real-time scene text localization and recognition. In: 2012 IEEE Conference on CVPR, pp. 3538–3545. IEEE (2012)
Cho, H., Sung, M., Jun, B.: Canny text detector: fast and robust scene text localization algorithm. In: CVPR, pp. 3566–3573 (2016)
Busta, M., Neumann, L., Matas, J.: Fastext: efficient unconstrained scene text detector. In: ICCV, pp. 1206–1214 (2015)
Zhong, Y., Zhang, H., Jain, A.K.: Automatic caption localization in compressed video. IEEE Trans. PAMI 22 (4), 385–392 (2000)
Hanif, S.M., Prevost, L., Negri, P.: A cascade detector for text detection in natural scene images. In: ICPR, pp. 1–4 (2008)
Hanif, S.M., Prevost, L.: Text detection and localization in complex scene images using constrained adaboost algorithm. In: ICDAR’09, pp. 1–5. IEEE (2009)
Zhang, Z., Shen, W., Yao, C., Bai, X.: Symmetry-based text line detection in natural scenes. In: CVPR, pp. 2558–2567 (2015)
Liang, G., Shivakumara, P., Lu, T., Tan, C.L.: A new wavelet-laplacian method for arbitrarily-oriented character segmentation in video text lines. In: ICDAR’15, pp. 926–930. IEEE (2015)
Huang, W., Qiao, Y., Tang, X.: Robust scene text detection with convolution neural network induced mser trees. In: ECCV, pp. 497–511. Springer (2014)
Zhong, Z., Sun, L., Huo, Q.: Improved localization accuracy by locnet for faster r-cnn based text detection. In: DICDAR’17, vol. 1, pp. 923–928. IEEE (2017)
Zhang, Z., Zhang, C., Shen, W., Yao, C., Liu, W., Bai, X.: Multi-oriented text detection with fully convolutional networks. In: CVPR, pp. 4159–4167 (2016)
Zhu, S., Zanibbi, R.: A text detection system for natural scenes with convolutional feature learning and cascaded classification. In: CVPR, pp. 625–632 (2016)
Qin, S., Manduchi, R.: Cascaded segmentation-detection networks for word-level text spotting. arXiv preprint arXiv:1704.00834 (2017)
Gupta, A., Vedaldi, A., Zisserman, A.: Synthetic data for text localisation in natural images. In: CVPR, pp. 2315–2324 (2016)
Tang, Y., Wu, X.: Scene text detection and segmentation based on cascaded convolution neural networks. IEEE Trans. Image Process. 26 (3), 1509–1520 (2017)
Article MATH Google Scholar
Wang, C., Yin, F., Liu, C.L.: Scene text detection with novel superpixel based character candidate extraction. In: ICDAR’17, vol. 1, pp. 929–934. IEEE (2017)
Turki, H., Halima, M.B., Alimi, A.M.: Text detection based on mser and cnn features. In: ICDAR’17, vol. 1, pp. 949–954. IEEE (2017)
Tian, S., Pan, Y., Huang, C., Lu, S., Yu, K., Lim Tan, C.: Text flow: a unified text detection system in natural scene images. In: ICCV, pp. 4651–4659 (2015)
Tian, Z., Huang, W., He, T., He, P., Qiao, Y.: Detecting text in natural image with connectionist text proposal network. In: ECCV, pp. 56–72. Springer (2016)
He, T., Huang, W., Qiao, Y., Yao, J.: Text-attentional convolutional neural network for scene text detection. IEEE Trans. Image Process. 25 (6), 2529–2541 (2016)
Article MathSciNet MATH Google Scholar
Fabrizio, J., Robert-Seidowsky, M., Dubuisson, S., Calarasanu, S., Boissel, R.: Textcatcher: a method to detect curved and challenging text in natural scenes. IJDAR 19 (2), 99–117 (2016)
Pei, W.Y., Yang, C., Kau, L.J., Yin, X.C.: Multi-orientation scene text detection with multi-information fusion. In: ICPR, pp. 657–662. IEEE (2016)
Yin, X.C., Pei, W.Y., Zhang, J., Hao, H.W.: Multi-orientation scene text detection with adaptive clustering. IEEE Trans. PAMI 37 (9), 1930–1937 (2015)
Kang, L., Li, Y., Doermann, D.: Orientation robust text line detection in natural images. In: CVPR, pp. 4034–4041 (2014)
Gomez, L., Karatzas, D.: Textproposals: a text-specific selective search algorithm for word spotting in the wild. Pattern Recognit. 70 , 60–74 (2017)
Zhou, X., Yao, C., Wen, H., Wang, Y., Zhou, S., He, W., Liang, J.: East: an efficient and accurate scene text detector. arXiv preprint arXiv:1704.03155 (2017)
Shi, B., Bai, X., Belongie, S.: Detecting oriented text in natural images by linking segments. In: CVPR, vol. 3 (2017)
Liu, Y., Jin, L.: Deep matching prior network: toward tighter multi-oriented text detection. In: CVPR, vol. 2, p. 8 (2017)
Sheshadri, K., Divvala, S.K.: Exemplar driven character recognition in the wild. In: BMVC, pp. 1–10 (2012)
Shi, C., Wang, C., Xiao, B., Zhang, Y., Gao, S., Zhang, Z.: Scene text recognition using part-based tree-structured character detection. In: CVPR, pp. 2961–2968. IEEE (2013)
Coates, A., Carpenter, B., Case, C., Satheesh, S., Suresh, B., Wang, T., Wu, D.J., Ng, A.Y.: Text detection and character recognition in scene images with unsupervised feature learning. In: ICDAR’11, pp. 440–445. IEEE (2011)
Yao, C., Bai, X., Shi, B., Liu, W.: Strokelets: a learned multi-scale representation for scene text recognition. In: CVPR, pp. 4042–4049 (2014)
Lee, C.Y., Bhardwaj, A., Di, W., Jagadeesh, V., Piramuthu, R.: Region-based discriminative feature pooling for scene text recognition. In: CVPR, pp. 4050–4057 (2014)
Lou, X., Kansky, K., Lehrach, W., Laan, C., Marthi, B., Phoenix, D., George, D.: Generative shape models: joint text recognition and segmentation with very little training data. In: NIPS, pp. 2793–2801 (2016)
Liang, G., Shivakumara, P., Lu, T., Tan, C.L.: Multi-spectral fusion based approach for arbitrarily oriented scene text detection in video images. IEEE Trans. Image Process. 24 (11), 4488–4501 (2015)
Elagouni, K., Garcia, C., Mamalet, F., Sébillot, P.: Combining multi-scale character recognition and linguistic knowledge for natural scene text OCR. In: 2012 10th IAPR International Workshop on Document Analysis Systems (DAS), pp. 120–124. IEEE (2012)
Phan, T.Q., Shivakumara, P., Tian, S., Tan, C.L.: Recognizing text with perspective distortion in natural scenes. In: ICCV, pp. 569–576. IEEE (2013)
Weinman, J.J., Butler, Z., Knoll, D., Feild, J.: Toward integrated scene text reading. IEEE Trans. PAMI 36 (2), 375–387 (2014)
Su, B., Lu, S.: Accurate scene text recognition based on recurrent neural network. In: ACCV, pp. 35–48. Springer (2014)
Ghosh, S.K., Valveny, E., Bagdanov, A.D.: Visual attention models for scene text recognition. arXiv preprint arXiv:1706.01487 (2017)
Shi, B., Wang, X., Lyu, P., Yao, C., Bai, X.: Robust scene text recognition with automatic rectification. In: CVPR, pp. 4168–4176 (2016)
Lee, C.Y., Osindero, S.: Recursive recurrent nets with attention modeling for OCR in the wild. In: CVPR, pp. 2231–2239 (2016)
He, P., Huang, W., Qiao, Y., Loy, C.C., Tang, X.: Reading scene text in deep convolutional sequences. AAAI 16 , 3501–3508 (2016)
Google Scholar
Yang, X., He, D., Zhou, Z., Kifer, D., Giles, C.L.: Learning to read irregular text with attention mechanisms. In: IJCAI, pp. 3280–3286 (2017)
Shi, B., Bai, X., Yao, C.: An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. PAMI 39 (11), 2298–2304 (2017)
Neumann, L., Matas, J.: Scene text localization and recognition with oriented stroke detection. In: ICCV, pp. 97–104 (2013)
Jaderberg, M., Vedaldi, A., Zisserman, A.: Deep features for text spotting. In: ECCV, pp. 512–528. Springer (2014)
Jaderberg, M., Simonyan, K., Vedaldi, A., Zisserman, A.: Reading text in the wild with convolutional neural networks. IJCV 116 (1), 1–20 (2016)
Article MathSciNet Google Scholar
Neumann, L., Matas, J.: Efficient scene text localization and recognition with local character refinement. In: ICDAR’15, pp. 746–750. IEEE (2015)
Neumann, L., Matas, J.: Real-time lexicon-free scene text localization and recognition. IEEE Trans. PAMI 38 (9), 1872–1885 (2016)
Yao, C., Bai, X., Liu, W.: A unified framework for multioriented text detection and recognition. IEEE Trans. Image Process. 23 (11), 4737–4749 (2014)
Liao, M., Shi, B., Bai, X., Wang, X., Liu, W.: Textboxes: a fast text detector with a single deep neural network. In: AAAI, pp. 4161–4167 (2017)
Ye, Q., Doermann, D.: Text detection and recognition in imagery: a survey. IEEE Trans. PAMI 37 (7), 1480–1500 (2015)
Zhu, Y., Yao, C., Bai, X.: Scene text detection and recognition: recent advances and future trends. Front. Comput. Sci. 10 (1), 19–36 (2016)
Yin, X.C., Zuo, Z.Y., Tian, S., Liu, C.L.: Text detection, tracking and recognition in video: a comprehensive survey. IEEE Trans. Image Process. 25 (6), 2752–2773 (2016)
Weinman, J.J.: Unified Detection and Recognition for Reading Text in Scene Images. University of Massachusetts Amherst, Amherst (2008)
Field, J.: Improving text recognition in images of natural scenes. PhD thesis, University of Massachusetts Amherst (2014)
Jaderberg, M.: Deep learning for text spotting. PhD thesis (2015)
Mishra, A.: Understanding Text in Scene Images. PhD thesis, International Institute of Information Technology Hyderabad (2016)
Bissacco, A., Cummins, M., Netzer, Y., Neven, H.: Photoocr: Reading text in uncontrolled conditions. In: ICCV, pp. 785–792. IEEE (2013)
Pan, Y.F., Hou, X., Liu, C.L.: Text localization in natural scene images based on conditional random field. In: ICDAR’09, pp. 6–10. IEEE (2009)
Pan, Y.F., Hou, X., Liu, C.L.: A hybrid approach to detect and localize texts in natural scene images. IEEE Trans. Image Process. 20 (3), 800–813 (2011)
Wang, Y., Shi, C., Xiao, B., Wang, C.: Mrf based text binarization in complex images using stroke feature. In: ICDAR’15, pp. 821–825. IEEE (2015)
Koo, H.I., Cho, N.I.: Text-line extraction in handwritten chinese documents based on an energy minimization framework. IEEE Trans. Image Process. 21 (3), 1169–1175 (2012)
Mishra, A., Alahari, K., Jawahar, C.: Top-down and bottom-up cues for scene text recognition. In: CVPR, pp. 2687–2694. IEEE (2012)
Sharma, N., Mandal, R., Sharma, R., Roy, P.P., Pal, U., Blumenstein, M.: Multi-lingual text recognition from video frames. In: ICDAR’15, pp. 951–955. IEEE (2015)
Canny, J.: A computational approach to edge detection. IEEE Trans. PAMI 8 , 679–698 (1986)
Fogel, I., Sagi, D.: Gabor filters as texture discriminator. Biol. Cybern. 61 (2), 103–113 (1989)
Mallat, S.G.: A theory for multiresolution signal decomposition: the wavelet representation. IEEE Trans. PAMI 11 (7), 674–693 (1989)
Van Loan, C.: Computational Frameworks for the Fast Fourier Transform. SIAM, Philadelphia (1992)
Book MATH Google Scholar
Jung, K., Kim, K.I., Jain, A.K.: Text information extraction in images and video: a survey. Pattern Recognit. 37 (5), 977–997 (2004)
Zuo, Z.Y., Tian, S., Pei, W.Y., Yin, X.C.: Multi-strategy tracking based text detection in scene videos. In: ICDAR’15, pp. 66–70. IEEE (2015)
Tian, S., Yin, X.C., Su, Y., Hao, H.W.: A unified framework for tracking based text detection and recognition from web videos. IEEE Trans. PAMI 40 (3), 542–554 (2018)
Shivakumara, P., Phan, T.Q., Tan, C.L.: A laplacian approach to multi-oriented text detection in video. IEEE Trans. PAMI 33 (2), 412–419 (2011)
Yousfi, S., Berrani, S.A., Garcia, C.: Deep learning and recurrent connectionist-based approaches for arabic text recognition in videos. In: ICDAR’15, pp. 1026–1030. IEEE (2015)
Yao, C., Bai, X., Liu, W., Ma, Y., Tu, Z.: Detecting texts of arbitrary orientations in natural images. In: CVPR, pp. 1083–1090. IEEE (2012)
Nicolaou, A., Bagdanov, A.D., Gómez, L., Karatzas, D.: Visual script and language identification. In: 2016 12th IAPR Workshop on Document Analysis Systems (DAS), pp. 393–398. IEEE (2016)
Shi, B., Bai, X., Yao, C.: Script identification in the wild via discriminative convolutional neural network. Pattern Recognit. 52 , 448–458 (2016)
Gomez, L., Nicolaou, A., Karatzas, D.: Improving patch-based scene text script identification with ensembles of conjoined networks. Pattern Recognit. 67 , 85–96 (2017)
Sharma, N., Mandal, R., Sharma, R., Pal, U., Blumenstein, M.: ICDAR 2015 competition on video script identification (cvsi 2015). In: ICDAR’15, pp. 1196–1200. IEEE (2015)
Delaye, A., Liu, C.L.: Contextual text/non-text stroke classification in online handwritten notes with conditional random fields. Pattern Recognit. 47 (3), 959–968 (2014)
Van Phan, T., Nakagawa, M.: Text/non-text classification in online handwritten documents with recurrent neural networks. In: ICFHR, pp. 23–28. IEEE (2014)
Sharma, N., Shivakumara, P., Pal, U., Blumenstein, M., Tan, C.L.: Piece-wise linearity based method for text frame classification in video. Pattern Recognit. 48 (3), 862–881 (2015)
Bai, X., Shi, B., Zhang, C., Cai, X., Qi, L.: Text/non-text image classification in the wild with convolutional neural networks. Pattern Recognit. 66 , 437–446 (2017)
Otsu, N.: A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 9 (1), 62–66 (1979)
Sauvola, J., Pietikäinen, M.: Adaptive document image binarization. Pattern Recognit. 33 (2), 225–236 (2000)
Yi, C., Tian, Y.: Localizing text in scene images by boundary clustering, stroke segmentation, and string fragment classification. IEEE Trans. Image Process. 21 (9), 4256–4268 (2012)
Howe, N.R.: Document binarization with automatic parameter tuning. IJDAR 16 (3), 247–258 (2013)
Zhang, Z., Wang, W.: A novel approach for binarization of overlay text. In: 2013 IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 4259–4264. IEEE (2013)
Tensmeyer, C., Martinez, T.: Document image binarization with fully convolutional neural networks. arXiv preprint arXiv:1708.03276 (2017)
Peng, X., Cao, H., Natarajan, P.: Using convolutional encoder–decoder for document image binarization. In: ICDAR’17, vol. 1, pp. 708–713. IEEE (2017)
Meng, G., Yuan, K., Wu, Y., Xiang, S., Pan, C.: Deep networks for degraded document image binarization through pyramid reconstruction. In: ICDAR’17, vol. 1, pp. 727–732. IEEE (2017)
Ha, J.W., Lee, B.J., Zhang, B.T.: Text-to-image retrieval based on incremental association via multimodal hypernetworks. In: 2012 IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 3245–3250. IEEE (2012)
Mishra, A., Alahari, K., Jawahar, C.: Image retrieval using textual cues. In: ICCV, pp. 3040–3047. IEEE (2013)
Karaoglu, S., Tao, R., Gevers, T., Smeulders, A.W.M.: Words matter: scene text for image classification and retrieval. IEEE Trans. Multimed. 19 (5), 1063–1076 (2017)
Rong, X., Yi, C., Tian, Y.: Unambiguous text localization and retrieval for cluttered scenes. In: CVPR, pp. 3279–3287. IEEE (2017)
Lucas, S.M., Panaretos, A., Sosa, L., Tang, A., Wong, S., Young, R.: ICDAR 2003 robust reading competitions. In: ICDAR’03, pp. 682–687. IEEE (2003)
Lucas, SM.: ICDAR 2005 text locating competition results. In: ICDAR’05, pp. 80–84. IEEE (2005)
Shahab, A., Shafait, F., Dengel, A.: ICDAR 2011 robust reading competition challenge 2: reading text in scene images. In: ICDAR’11, pp. 1491–1496. IEEE (2011)
Karatzas, D., Shafait, F., Uchida, S., Iwamura, M., i Bigorda, L.G., Mestre, S.R., Mas, J., Mota, D.F., Almazan, J.A., de las Heras, L.P.: ICDAR 2013 robust reading competition. In: ICDAR’13, pp. 1484–1493. IEEE (2013)
Karatzas, D., Gomez-Bigorda, L., Nicolaou, A., Ghosh, S., Bagdanov, A., Iwamura, M., Matas, J., Neumann, L., Chandrasekhar, V.R., Lu, S., et al.: ICDAR 2015 competition on robust reading. In: ICDAR’15, pp. 1156–1160. IEEE (2015)
Veit, A., Matera, T., Neumann, L., Matas, J., Belongie, S.: Coco-text: Dataset and benchmark for text detection and recognition in natural images. arXiv preprint arXiv:1601.07140 (2016)
Mishra, A., Alahari, K., Jawahar, C.: Scene text recognition using higher order language priors. In: BMVC, BMVA (2012)
Campos, T.E.D., Babu, B.R., Varma, A.M.: Character Recognition in Natural Images. Chapman & Hall, Boca Raton (2009)
SeongHun, L., Min Su, C., Kyomin, J., Jin Hyung, K.: Scene text extraction with edge constraint and text collinearity. In: 2010 20th International Conference on Pattern Recognition, pp. 3983–3986. IEEE (2010)
Yi, C., Tian, Y.: Text string detection from natural scenes by structure-based partition and grouping. IEEE Trans. Image Process. 20 (9), 2594–2605 (2011)
Ch’ng, C.K., Chan, C.S.: Total-text: a comprehensive dataset for scene text detection and recognition. In: 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), vol. 1, pp. 935–942. IEEE (2017)
Shi, B., Yao, C., Liao, M., Yang, M., Xu, P., Cui, L., Belongie, S., Lu, S., Bai, X.: ICDAR 2017 competition on reading chinese text in the wild (rctw-17). arXiv preprint arXiv:1708.09585 (2017)
Risnumawan, A., Shivakumara, P., Chan, C.S., Tan, C.L.: A robust arbitrary text detection system for natural scene images. Expert Syst. Appl. 41 (18), 8027–8048 (2014)
Wolf, C., Jolion, J.M.: Object count/area graphs for the evaluation of object detection and segmentation algorithms. IJDAR 8 (4), 280–296 (2006)
Cheng, Z., Bai, F., Xu, Y., Zheng, G., Pu, S., Zhou, S.L Focusing attention: towards accurate text recognition in natural images. In: ICCV, pp. 5086–5094. IEEE (2017)
Jaderberg, M., Simonyan, K., Vedaldi, A., Zisserman, A.: Deep structured output learning for unconstrained text recognition. In: ICLR (2015)
Alsharif, O., Pineau, J.: End-to-end text recognition with hybrid hmm maxout models. arXiv preprint arXiv:1310.1811 (2013)
Wang, K., Babenko, B., Belongie, S.: End-to-end scene text recognition. In: ICCV, pp. 1457–1464. IEEE (2011)
Li, H., Wang, P., Shen, C.: Towards end-to-end text spotting with convolutional recurrent neural networks. In: Proc. ICCV, pp. 5238–5246 (2017)
Hu, H., Zhang, C., Luo, Y., Wang, Y., Han, J., Ding, E.: Wordsup: exploiting word annotations for character based text detection. In: ICCV (2017)
He, W., Zhang, X.Y., Yin, F., Liu, C.L.: Deep direct regression for multi-oriented scene text detection. arXiv preprint arXiv:1703.08289 (2017)
He, P., Huang, W., He, T., Zhu, Q., Qiao, Y., Li, X.: Single shot text detector with regional attention. In: ICCV (2017)
Busta, M., Neumann, L., Matas, J.: Deep textspotter: an end-to-end trainable scene text localization and recognition framework. In: ICCV, pp. 22–29 (2017)
Wu, Y., Natarajan, P.: Self-organized text detection with minimal post-processing via border learning. In: CVPR, pp. 5000–5009 (2017)
Gordo, A.: Supervised mid-level features for word image representation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2956–2964 (2015)
Almazan, J., Gordo, A., Fornes, A., Valveny, E.: Word spotting and recognition with embedded attributes. IEEE Trans. PAMI 36 (12), 2552–2566 (2014)
Download references
Acknowledgements
This work was supported by the National Natural Science Foundation of China under Grants 61370039, and the Beijing Natural Science Foundation under Grant L172053.
Author information
Authors and affiliations.
National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences, Beijing, 100190, People’s Republic of China
Xiyan Liu, Gaofeng Meng & Chunhong Pan
School of Artificial Intelligence, University of Chinese Academy of Sciences, Beijing, 100049, People’s Republic of China
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Gaofeng Meng .
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Reprints and permissions
About this article
Liu, X., Meng, G. & Pan, C. Scene text detection and recognition with advances in deep learning: a survey. IJDAR 22 , 143–162 (2019). https://doi.org/10.1007/s10032-019-00320-5
Download citation
Received : 27 September 2017
Revised : 26 February 2019
Accepted : 06 March 2019
Published : 27 March 2019
Issue Date : 01 June 2019
DOI : https://doi.org/10.1007/s10032-019-00320-5
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Natural image
- Text detection
- Text recognition
- Find a journal
- Publish with us
- Track your research
RIT graduate pursues Ph.D. across time zones

Nastaran Nagshineh, center, defended her Ph.D. thesis at RIT in April. Faculty from RIT’s Rochester and Dubai campuses served on her thesis committee and include, from left to right, Kathleen Lamkin-Kennard, Steven Weinstein, Nathaniel Barlow, and David Kofke (a professor at the University at Buffalo). Mohamed Samaha participated remotely and appears on the video screen behind the group and alongside Nagshineh’s picture.
Nastaran Nagshineh is one of the first Ph.D. candidates to bridge RIT’s Rochester and Dubai campuses. Her accomplishment creates a path for future students at the university’s international campuses.
Nagshineh completed her Ph.D. in mathematical modeling while working full time as a mathematics lecturer at RIT Dubai in the United Arab Emirates, teaching as many as five classes a semester. She described her Ph.D. journey as “an exercise in perseverance” due to competing demands and long days. Rochester is eight hours behind Dubai, and the time difference meant many late-night classes and meetings.
“I saw this collaboration as an opportunity, rather than as a challenge, because my primary adviser, Dr. Steven Weinstein (RIT professor of chemical engineering), and my co-adviser, Dr. Mohamed Samaha (RIT Dubai associate professor of mechanical engineering), both have the same area of research interest,” she said. “They both worked toward my success.”
Nagshineh is one of 67 RIT Ph.D. students who defended their thesis this academic year and who will earn their doctorate. RIT awarded 63 Ph.D. degrees in 2023.
In 2020-2021, RIT’s Graduate School met and surpassed the university’s goal of conferring 50 Ph.D. degrees during an academic year. That number will continue to grow as students cycle through the seven new Ph.D. programs that RIT has added since 2017, said Diane Slusarski , dean of RIT’s Graduate School.
Meeting these goals puts RIT on a path toward achieving an “R1,” or research-intensive designation, from the Carnegie Classification of Institutions of Higher Learning. RIT is currently ranked as an R2 institution . Many factors go into changing a university’s status, including research investment and maintaining a three-year average of 70 Ph.D. degrees awarded per year, according to Slusarski.
“We have met the goals of the strategic plan, and now we look forward to contributing to the research innovation in the future,” Slusarski said. “We want to help the new programs thrive and win national research awards.”
RIT’s emphasis on high-level research is seen in Nagshineh’s Ph.D. work. She applies mathematical modeling to the field of fluid dynamics. Her research has been published in top-tier journals and has gained notice, said Weinstein, her thesis adviser.
Weinstein describes Nagshineh’s accomplishments as “a testament to a fantastic work ethic and commitment” and is inspirational to younger students at Rochester and Dubai.
“The collaboration between RIT Dubai/Rochester has continued,” he said. “Another paper was submitted a few weeks ago with Mohamed Samaha and Nate Barlow (RIT associate professor in the School of Mathematics and Statistics) as co-authors, as well as Cade Reinberger, a younger Ph.D. student in my research group.”
Mathematical modeling is one of RIT’s newer Ph.D. degree programs, and Nagshineh is among its earliest graduates. The program has doubled in size since it began accepting students in 2017, Slusarski said. This past fall, the mathematical modeling program had 35 students, with two graduating this year.
Altogether, RIT has 13 Ph.D. degree programs currently enrolling 438 students, with computing and information sciences accounting for the largest with 117 students. RIT’s other Ph.D. programs include astrophysical sciences and technology , biomedical and chemical engineering , business administration , color science , electrical and computer engineering, imaging science , mechanical and industrial engineering , microsystems engineering , and sustainability .
New programs in cognitive science and physics will launch in the fall.
The growth in RIT graduate education—with more than 3,000 master’s and doctoral students—reflects a demographic change in the student population, Slusarski said. “We have a higher percentage of women in the graduate programs than we have for RIT undergraduate programs.”
RIT’s graduate programs enroll 42 percent women, according to Christie Leone , assistant dean for the Graduate School.
Nagshineh, who also holds an MS in electrical engineering from RIT Dubai, welcomes her role as a mentor to other women students on both campuses.
“As a young woman in an Arabic country, the power of women is often underestimated and undervalued, and I hope to serve as a role model to female students, especially those that question their path,” Nagshineh said.
She plans to continue in her career as a professor and a researcher. “I would like to pursue a research program where I can advise my own students and teach them more deeply.”
Recommended News
May 17, 2024

Top Teacher: Minnetonka sign language teacher Dr. Tracy Ivy
KMSP-TV selects Tracy Ivy '09 (secondary education for students who are deaf or hard of hearing) as a Top Teacher.
May 16, 2024

Kim Shearer’s passion for planning spans five decades at RIT
Kim Shearer's journey at RIT, marked by strategic planning and dedication, led to pivotal roles in shaping the university's computing college, spearheading expansions, fostering diversity, and leaving behind unique touches like binary code lights and cryptic messages within the campus architecture.
May 15, 2024

RIT student-faculty developed video game ‘That Damn Goat’ now available for purchase on Nintendo Switch console
A video game created by RIT students and faculty has reached a long-awaited milestone. That Damn Goat , developed and published through RIT’s MAGIC Spell Studios, is now available for purchase on the popular Nintendo Switch gaming console.

RIT researchers expect a rise in deepfake use in political campaigns
Spectrum News interviews Christopher Schwartz, research scientist in the Department of Cybersecurity, and Kelly Wu, computing and information sciences Ph.D. student, about generating and detecting artificial intelligence deepfakes.
Cookies on GOV.UK
We use some essential cookies to make this website work.
We’d like to set additional cookies to understand how you use GOV.UK, remember your settings and improve government services.
We also use cookies set by other sites to help us deliver content from their services.
You have accepted additional cookies. You can change your cookie settings at any time.
You have rejected additional cookies. You can change your cookie settings at any time.
- Business and industry
- Business and the environment
National recognition at UK Procurement Awards for Sellafield
Recognition at UK national awards for Sellafield Ltd and The Programme and Project Partners.

From the left: Marie Oglanby, Emily Zanacchi, Lisa Lane, Joanne Griffin, Jason McCann, Christine Davies, Karolina Kosik, Mahmuda Begum, James Riddick, Andrew Van Schaick and Jonathan Williams.
Congratulations to all the winners and those who were shortlisted at the UK National GO Procurement Awards 23/24, which were hosted in Liverpool this week.
The GO Awards are the UK’s leading public procurement excellence awards, celebrating the very best procurement achievements from across the UK’s public, private and third sector organisations.
Sellafield Ltd were highly commended in the ‘Team of the Year Award’ and our Programme and Project Partners were also highly commended in the ‘Procurement of the Year Award’ and the ‘Social Value Award’ categories.
James Riddick, chief supply chain officer, Sellafield Ltd said:
Being awarded highly commended for 3 awards against strong national competition is a testament to the quality of the work that Sellafield Ltd undertakes in collaboration with the supply chain in the delivery of its nationally important mission. It’s evident from my first few weeks in post that the nuclear sector is filled with passionate and dedicated people who care about the future of the industry and the organisations and communities that support it.
Sellafield Ltd procurement lead, Karolina Kosik on behalf of the ‘Team of the Year Award’ said:
Having worked in the Sellafield Ltd Supply Chain Directorate Team for a few years now, I’m really proud of our work being recognised. We deliver a breadth of complex activity across the full commercial lifecycle as well as delivering above and beyond strategic value in what we do. We have a great team of professionals who work to high standards and support each other day by day. I’m really pleased we have been recognised for making a positive difference.
James Fennell, head of commercial for Programme and Programme Partners, said:
One of the benefits of a long-term relationship with the supply chain in the Programme and Project Partners, is the ability to work together more closely to understand and help respond to social and economic opportunities. One example is the ‘Chapter One’ reading programme, which now has many reading volunteers who engage with children to boost their reading abilities to help them for their futures. Another example is the several strategic sub tier long-term contracts now in place to allow organisations in lower supply chain tiers to invest for their futures. I feel proud that the partners are recognised in this area.

The ‘Chapter One’ reading programme
For being highly commended in the ‘Procurement of the Year Award’, Andy Van Schaick, head of supply chain strategy for Sellafield Ltd, said:
The approach taken in the development of the operating and commercial model and the procurement execution of the Programme and Project Partners, is now realising great benefits. At the time the procurement approach was a step change for Sellafield Ltd and industry. I’m proud of how procurement activity has enabled strategic change in the delivery of a portfolio of complex major projects.
Further reading
How to do business with Sellafield Ltd
UK National Go Awards
Share this page
The following links open in a new tab
- Share on Facebook (opens in new tab)
- Share on Twitter (opens in new tab)
Is this page useful?
- Yes this page is useful
- No this page is not useful
Help us improve GOV.UK
Don’t include personal or financial information like your National Insurance number or credit card details.
To help us improve GOV.UK, we’d like to know more about your visit today. Please fill in this survey (opens in a new tab) .
- Election 2024
- Entertainment
- Newsletters
- Photography
- Personal Finance
- AP Investigations
- AP Buyline Personal Finance
- AP Buyline Shopping
- Press Releases
- Israel-Hamas War
- Russia-Ukraine War
- Global elections
- Asia Pacific
- Latin America
- Middle East
- Election Results
- Delegate Tracker
- AP & Elections
- Auto Racing
- 2024 Paris Olympic Games
- Movie reviews
- Book reviews
- Personal finance
- Financial Markets
- Business Highlights
- Financial wellness
- Artificial Intelligence
- Social Media
UN assembly approves resolution granting Palestine new rights and reviving its UN membership bid
The U.N. General Assembly voted by a wide margin on Friday to grant new “rights and privileges” to Palestine and called on the Security Council to favorably reconsider its request to become the 194th member of the United Nations.
FILE - Palestinian President Mahmoud Abbas addresses the 77th session of the United Nations General Assembly on Sept. 23, 2022, at the U.N. headquarters. The U.N. General Assembly is expected to vote Friday, May 10, 2024, on a resolution that would grant new “rights and privileges” to Palestine and call on the Security Council to favorably reconsider its request to become the 194th member of the United Nations. (AP Photo/Julia Nikhinson, File)
- Copy Link copied
UNITED NATIONS (AP) — The U.N. General Assembly voted by a wide margin on Friday to grant new “rights and privileges” to Palestine and called on the Security Council to reconsider Palestine’s request to become the 194th member of the United Nations.
The world body approved the Arab and Palestinian-sponsored resolution by a vote of 143-9 with 25 abstentions. The United States voted against it, along with Israel, Argentina, Czechia, Hungary, Micronesia, Nauru, Palau and Papua New Guinea.
The vote reflected the wide global support for full membership of Palestine in the United Nations, with many countries expressing outrage at the escalating death toll in Gaza and fears of a major Israeli offensive in Rafah, a southern city where about 1.3 million Palestinians have sought refuge.
It also demonstrated growing support for the Palestinians. A General Assembly resolution on Oct. 27 calling for a humanitarian cease-fire in Gaza was approved 120-14 with 45 abstentions. That was just weeks after Israel launched its military offensive in response to Hamas’ Oct. 7 attack in southern Israel, which killed 1,200 people.
While Friday’s resolution gives Palestine some new rights and privileges, it reaffirms that it remains a non-member observer state without full U.N. membership and the right to vote in the General Assembly or at any of its conferences. And the United States has made clear that it will block Palestinian membership and statehood until direct negotiations with Israel resolve key issues, including security, boundaries and the future of Jerusalem, and lead to a two-state solution.
U.S. deputy ambassador Robert Wood said Friday that for the U.S. to support Palestinian statehood, direct negotiations must guarantee Israel’s security and future as a democratic Jewish state and that Palestinians can live in peace in a state of their own.
The U.S. also vetoed a widely backed council resolution on April 18 that would have paved the way for full United Nations membership for Palestine.
Under the U.N. Charter, prospective members of the United Nations must be “peace-loving” and the Security Council must recommend their admission to the General Assembly for final approval. Palestine became a U.N. non-member observer state in 2012.
The United States considers Friday’s resolution an attempt to get around the Charter’s provisions, Wood reiterated Thursday.
Unlike resolutions in the Security Council, there are no vetoes in the 193-member General Assembly. Friday’s resolution required a two-thirds majority of members voting and got significantly more than the 118 vote minimum.
U.S. allies supported the resolution, including France, Japan, South Korea, Spain, Australia, Estonia and Norway. But European countries were very divided.
The resolution “determines” that a state of Palestine is qualified for membership — dropping the original language that in the General Assembly’s judgment it is “a peace-loving state.” It therefore recommends that the Security Council reconsider its request “favorably.”
The renewed push for full Palestinian membership in the U.N. comes as the war in Gaza has put the more than 75-year-old Israeli-Palestinian conflict at center stage. At numerous council and assembly meetings, the humanitarian crisis facing the Palestinians in Gaza and the killing of more than 34,000 people in the territory, according to Gaza health officials, have generated outrage from many countries.
Before the vote, Riyad Mansour, the Palestinian U.N. ambassador, told the assembly in an emotional speech that “No words can capture what such loss and trauma signifies for Palestinians, their families, communities and for our nation as a whole.”
He said Palestinians in Gaza “have been pushed to the very edge of the strip, to the very brink of life” with Israel besieging Rafah.
Mansour accused Israel’s Prime Minister Benjamin Netanyahu of preparing “to kill thousands to ensure his political survival” and aiming to destroy the Palestinian people.
He welcomed the resolution’s strong support and told AP that 144 countries have now recognized the state of Palestine, including four countries since Oct. 7, all from the Caribbean.
Israel’s U.N. Ambassador Gilad Erdan vehemently opposed the resolution, accusing U.N. member nations of not mentioning Hamas’ Oct. 7 attack and seeking “to reward modern-day Nazis with rights and privileges.”
He said if an election were held today, Hamas would win, and warned U.N. members that they were “about to grant privileges and rights to the future terror state of Hamas.” He held up a photo of Yehya Sinwar, the mastermind of the Hamas attack on Israel, saying a terrorist “whose stated goal is Jewish genocide” would be a future Palestinian leader.
Erdan also accused the assembly of trampling on the U.N. Charter, putting two pages that said “U.N. Charter” in a small shredder he held up. .
The original draft of the resolution was changed significantly to address concerns not only by the U.S. but also by Russia and China, three Western diplomats said, speaking on condition of anonymity because negotiations were private.
The first draft would have conferred on Palestine “the rights and privileges necessary to ensure its full and effective participation” in the assembly’s sessions and U.N. conferences “on equal footing with member states.” It also made no reference to whether Palestine could vote in the General Assembly.
According to the diplomats, Russia and China, which are strong supporters of Palestine’s U.N. membership, were concerned that granting the rights and privileges listed in an annex could set a precedent for other would-be U.N. members — with Russia concerned about Kosovo and China about Taiwan.
Under longstanding legislation by the U.S. Congress, the United States is required to cut off funding to U.N. agencies that give full membership to a Palestinian state, which could mean a cutoff in dues and voluntary contributions to the U.N. from its largest contributor.
The final draft that was voted on dropped the language that would put Palestine “on equal footing with member states.” And to address Chinese and Russian concerns, it decided “on an exceptional basis and without setting a precedent” to adopt the rights and privileges in the annex.
It also added a provision in the annex clarifying that it does not give Palestine the right to vote in the General Assembly or put forward candidates for U.N. agencies.
What the resolution does give Palestine are the rights to speak on all issues not just those related to the Palestinians and Middle East, to propose agenda items and reply in debates, and to serve on the assembly’s main committees. It also allows Palestinians to participate in U.N. and international conferences convened by the United Nations, but without the right to vote.
Palestinian President Mahmoud Abbas first delivered the Palestinian Authority’s application for U.N. membership in 2011. It failed because the Palestinians didn’t get the required minimum support of nine of the Security Council’s 15 members.
They went to the General Assembly and succeeded by more than a two-thirds majority in having their status raised from a U.N. observer to a non-member observer state. That opened the door for the Palestinian territories to join U.N. and other international organizations, including the International Criminal Court.
In the Security Council vote on April 18, the Palestinians got much more support for full U.N. membership. The vote was 12 in favor, the United Kingdom and Switzerland abstaining, and the United States voting no and vetoing the resolution.
Follow AP’s coverage at https://apnews.com/hub/israel-hamas-war
- Search Menu
- Chemical Biology and Nucleic Acid Chemistry
- Computational Biology
- Critical Reviews and Perspectives
- Data Resources and Analyses
- Gene Regulation, Chromatin and Epigenetics
- Genome Integrity, Repair and Replication
- Methods Online
- Molecular Biology
- Nucleic Acid Enzymes
- RNA and RNA-protein complexes
- Structural Biology
- Synthetic Biology and Bioengineering
- Advance Articles
- Breakthrough Articles
- Special Collections
- Scope and Criteria for Consideration
- Author Guidelines
- Data Deposition Policy
- Database Issue Guidelines
- Web Server Issue Guidelines
- Submission Site
- About Nucleic Acids Research
- Editors & Editorial Board
- Information of Referees
- Self-Archiving Policy
- Dispatch Dates
- Advertising and Corporate Services
- Journals Career Network
- Journals on Oxford Academic
- Books on Oxford Academic
Article Contents
- Introduction
- Materials and methods
- Data availability
- Supplementary data
- Acknowledgements
- < Previous
The nuclease-associated short prokaryotic Argonaute system nonspecifically degrades DNA upon activation by target recognition
- Article contents
- Figures & tables
- Supplementary Data
Xueling Lu, Jun Xiao, Longfei Wang, Bin Zhu, Fengtao Huang, The nuclease-associated short prokaryotic Argonaute system nonspecifically degrades DNA upon activation by target recognition, Nucleic Acids Research , Volume 52, Issue 2, 25 January 2024, Pages 844–855, https://doi.org/10.1093/nar/gkad1145
- Permissions Icon Permissions
Prokaryotic Argonautes (pAgos) play a vital role in host defense by utilizing short nucleic acid guides to recognize and target complementary nucleic acids. Despite being the majority of pAgos, short pAgos have only recently received attention. Short pAgos are often associated with proteins containing an APAZ domain and a nuclease domain including DUF4365, SMEK, or HNH domain. In contrast to long pAgos that specifically cleave the target DNA, our study demonstrates that the short pAgo from Thermocrispum municipal , along with its associated DUF4365-APAZ protein, forms a heterodimeric complex. Upon RNA-guided target DNA recognition, this complex is activated to nonspecifically cleave DNA. Additionally, we found that the TmuRE-Ago complex shows a preference for 5′-OH guide RNA, specifically requires a uridine nucleotide at the 5′ end of the guide RNA, and is sensitive to single-nucleotide mismatches between the guide RNA and target DNA. Based on its catalytic properties, our study has established a novel nucleic acid detection method and demonstrated its feasibility. This study not only expands our understanding of the defense mechanism employed by short pAgo systems but also suggests their potential applications in nucleic acid detection.

Email alerts
Citing articles via.
- Editorial Board
Affiliations
- Online ISSN 1362-4962
- Print ISSN 0305-1048
- Copyright © 2024 Oxford University Press
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Open access
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
IMAGES
VIDEO
COMMENTS
Here, we conduct researches on text detection and recognition based on CNN and LSTM, as presented below. 1. To improve the recall rate of small text areas in oriented text detection, we propose an Xception-based multi-ASPP-assembled scene text detector named DeepText. DeepText inserts multiple Atrous Spatial Pyramid Pooling (ASPP) modules into ...
The text recognition models based on deep learning achieve better results than traditional method. The text recognition algorithms based on deep learning mainly include image correction, feature extraction, sequence prediction and so on. The recognition process is shown in Fig. 2. Firstly, the input text is corrected to be horizontally arranged.
The final part of the thesis presents a novel approach for text spotting, which is a new framework for an end-to-end character detection and recognition system designed using an improved SSD convolutional neural network, wherein layers are added to the SSD networks and the aspect ratio of the characters is considered because it is different from that of the other objects.
Scene text detection is a prerequisite for scene text recognition. However, most existing approaches to scene text detection only utilize single source of deep features, which is vulnerable to changes of feature distributions. ... PhD thesis, Xidian university (2017) Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale ...
This thesis focuses on modifying the open source speech recognition toolkit, Kaldi, to work for the task of handwriting recognition, also called text recog- ... Text recognition is a process of converting a sequence of image/pixel vectors into a sequence of words. In an hidden markov model (HMM) based text
Handwritten text recognition (HTR) on character sequences is an open research problem because it is harder to segment and recognize individual characters, rather words [].Moreover, transcription models must solve the problem of finding and classifying characters at each time-step without knowing the alignment between the input sequence of image pixels and the target sequence of characters [].
Certificate of Authorship/Originality I, Qingqing Wang, declare that this thesis is submitted in fulfilment of the require-ments for the award of Doctor of Philosophy in the Faculty of Engineering and
Automated Text Recognition Mohamad A. Akra This report is based on the unaltered thesis of Mohamad A. Akra submitted to the Department of Electrical Engineering and Computer Science in partial fulfillment of the requirements for the degree of Doctor of Philosophy at the Massachusetts Institute of Technology in August 1993.
Source: Liu, Z. (2020). Deep learning methods for scene text detection. Doctoral thesis, Nanyang Technological University, Singapore. Abstract: Optical Character Recognition (OCR) is a common method to convert typed, hand-written or printed text from documents and scene photos into digital format, which can be edited, searched, stored and ...
The objective of this thesis is the study of the Handwritten Text Recognition problem with the use of deep learning models. In this thesis, we experiment with a variety of tasks that apply to the ...
State-of-the-art handwritten text recognition models make frequent use of deep neural networks, with recurrent and connectionist temporal classification layers, which perform recognition over sequences of characters. ... Master's thesis, The University of Haifa (2018) Google Scholar Goodfellow, I., Bengio, Y., Courville, A.: Deep Learning ...
Handwritten Text Recognition (HTR) is an active area of research, combining ideas from both computer vision and natural language processing. ... Ph.D. thesis, Verlag nicht ermittelbar (2012) [8] Graves, A.: Connectionist temporal classification. In: Supervised Sequence Labelling with Recurrent Neural Networks, pp. 61-93. Springer (2012)
Traditionally text recognition has focused on documents, and several optical character recognition (OCR) techniques have been developed for this task. Recently, text detection in scene imagery has come to the forefront. Generally, text recognition works by rst providing a \candidate bounding box" - or a proposal for a single word or a word-line.
to written text will help people more effectively access, search, share, and analyze their records, while still allow-ing them to use their preferred writing method. The aim of this project is to further explore the task of classifying handwritten text and to convert handwritten text into the digital format. Handwritten text is a very gen-
Scene text recognition has generated significant interest from many branches of research. While it is now possible to achieve extremely high performance on tasks such as digit recognition in controlled settings [9], the task of detecting and labeling characters in complex scenes remains an active research topic. However, many of the methods
of annotated scene text images for training accurate and robust scene text detection and recognition models. The proposed technique consists of three innovative designs. First, it realizes \semantic coherent" syn-thesis by embedding texts at semantically sensible regions within the background image, where the semantic coherence is achieved by ...
This Thesis addresses the offline continuous handwritten text recognition (HTR) problem, consisting of developing algorithms and models capable of transcribing the text present in an image without the need for the text to be segmented into characters. For this purpose, we have proposed a new recognition model based on integrating two types of ...
In this thesis, we look at all the parameters involved in the process of text recognition and determine the importance of those parameters through thorough experiments. We use synthetic data for controlled experiments where we test the parameters as mentioned earlier in an isolated fashion to effectively iden-tify the catalysts of text recognition.
Handwritten Text Recognition using Deep. Learning (CNN & RNN) Rohini G. Khalkar, Adarsh Singh Dikhit, Anirudh Goel, Manisha Gupta4. Assistant professor, Department of Computer E ngineering ...
Hafumbuku: A Text Recognition Model for the Manchu Script¯ Chao Cheng Advised by George A. Alvarez & Mark C. Elliott Presented to the Department of Computer Science and the Department of East Asian Languages and Civilizations in partial fulfillment of the requirements for the degree with honors of Bachelor of Arts Harvard College Cambridge ...
The process of text recognition starts with capturing the image of the required document, preprocessing it to acquire the desired portion and then segmenting it to extract the text content present in it. This paper discusses different stages in the task of text recognition from images. LITERATURE REVIEW.
Conclusion and Future Direction. In this paper, proposed a text-based emotion recognition model. The proposed model is a combination of deep learning and machine learning approaches. This proposed hybrid approach uses the combination of three datasets, namely, ISEAR, WASSA, and the Emotion-Stimulus dataset.
Optical Character Recognition (OCR) with GPT-4o. OCR is a common computer vision task to return the visible text from an image in text format. Here, we prompt GPT-4o to "Read the serial number." and "Read the text from the picture", both of which it answers correctly. GPT-4o prompted with OCR questions
Hui Wu and Bing Li, "License Plate Recognition System," in International Conference on Multimedia Technology (ICMT), 2011, pp. 5425-5427. H. Erdinc Kocer and K. Kursat Cevik, "Artificial neural netwokrs based vehicle license plate recognition," Procedia Computer Science, vol. 3, pp. 1033-1037, 2011.
Scene text detection and recognition has become a very active research topic in recent several years. It can find many applications in reality ranging from navigation for vision-impaired people to semantic natural scene understanding. In this survey, we are intended to give a thorough and in-depth reviews on the recent advances on this topic, mainly focusing on the methods that appeared in the ...
RIT awarded 63 Ph.D. degrees in 2023. In 2020-2021, RIT's Graduate School met and surpassed the university's goal of conferring 50 Ph.D. degrees during an academic year. That number will continue to grow as students cycle through the seven new Ph.D. programs that RIT has added since 2017, said Diane Slusarski, dean of RIT's Graduate School.
Published. 17 May 2024. From the left: Marie Oglanby, Emily Zanacchi, Lisa Lane, Joanne Griffin, Jason McCann, Christine Davies, Karolina Kosik, Mahmuda Begum, James Riddick, Andrew Van Schaick ...
Accurate bird species recognition is crucial for ecological conservation, wildlife monitoring, and biological research, yet it poses significant challenges due to the high variability within species and the subtle similarities between different species. This paper introduces an automatic bird species recognition method from images that leverages feature enhancement and contrast learning to ...
UNITED NATIONS (AP) — The U.N. General Assembly voted by a wide margin on Friday to grant new "rights and privileges" to Palestine and called on the Security Council to reconsider Palestine's request to become the 194th member of the United Nations. The world body approved the Arab and Palestinian-sponsored resolution by a vote of 143-9 ...
Upon RNA-guided target DNA recognition, this complex is activated to nonspecifically cleave DNA. Additionally, we found that the TmuRE-Ago complex shows a preference for 5′-OH guide RNA, specifically requires a uridine nucleotide at the 5′ end of the guide RNA, and is sensitive to single-nucleotide mismatches between the guide RNA and ...